RNNの中で使われる、過去の重要な点に着目するための手法で、各隠れ層を重み付けする。
context vectorによって重み付けすることで、各単語が参照すべき重要な単語を見分けることで、 説明可能なAIを作成する。(AIがどこに注意したのか可視化できるため)
2020年06月04日
5月29日、5月最後の平日であるこの日、13回目となる勉強会が開催されました。
テーマは「WebRTC」、そして、「AIと芸術」でした。
ブラウザー間での通信を実現させるWebRTC。
そして近年注目を集める、AIによる芸術、創作について。
この春に入社した、新入社員のお二人から発表が行われました。

WebRTC(Web Real Time Communication)とは、Webブラウザ間でリアルタイムなコミュニケーションを実装することを目的としたオープンソースプロジェクトです。
これを実現するために、P2PやICEといった技術が利用されています。
そもそもP2P(Peer-to-Peer)通信とは、特定のサーバーを介さずに、端末同士がやりとりをする通信方式のことです。
一般に、ネットワークというと、中心となるサーバーがあって、そのサーバーを介してクライアント同士がやりとりをする、いわゆるclient-server型のネットワークが思い浮かぶかもしれません。
しかし、P2P通信とは、クライアント同士がサーバーを介さずに直接やり取りする通信方式のことです。
P2Pでは、接続したい端末のIPアドレスといった、接続相手の情報が既知である必要があります。
そこで、多くの場合、通信者同士の情報を交換する(シグナリング)ためのサーバを用意しておくことが一般的です。
これをSignalingサーバーといいます。
ちなみにWebRTCでは、Signalingサーバーとクライアント間の通信方式は特に定められていません。
このSignalingサーバーを経由して、クライアントは通信相手と接続するための情報を送受信することができます。
実際に、クライアント同士での通信を実現させるために、WebRTCでは、ICEというフレームワークを利用しています。
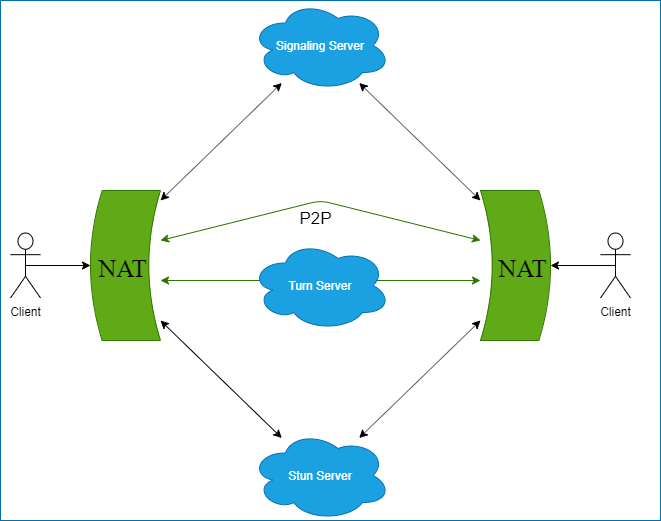
ICEは、通信したいクライアント同士の、あらゆるネットワークの状況を想定し、接続を試みるためのフレームワークです。
例えば、同一ネットワークに所属しているなどの特殊な場合を除いて、 通信者同士はそれぞれ別のNAT配下にいることがほとんどでしょう。この場合は、NATを超えて通信をする必要があります。
ICEにおいて、これを実現するために登場してくるのが、StunサーバーとTurnサーバーです。
Stunサーバーは、リクエストを送ると、外側(インターネット)から見た自分のIPを返すサーバーです。
ICEではまず、Stunサーバーから返ってきたIPを使い、クライアント同士の通信を試みます。
これでも接続ができなかった場合は、Turnサーバーを経由して接続を試み、以後全ての通信をTurnサーバー経由で行います。
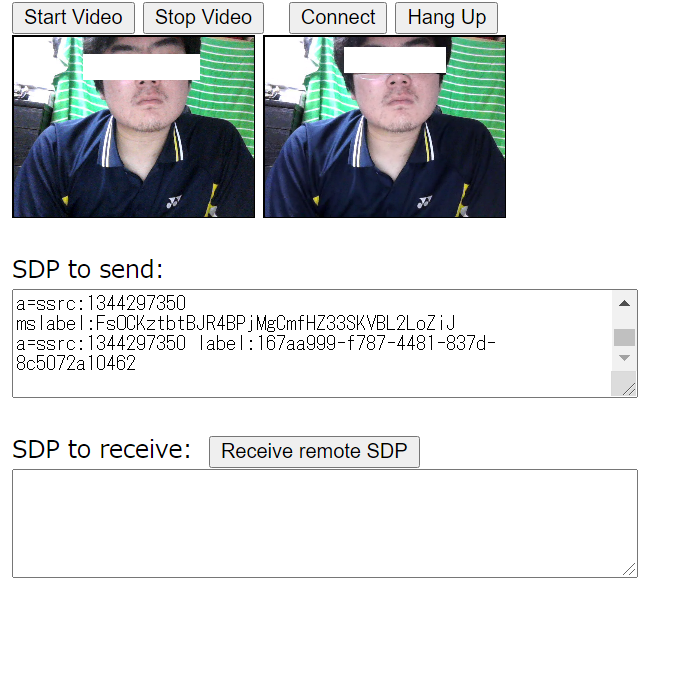
勉強会では、社員によるWebRTCのサンプルを使った実演が行われました。
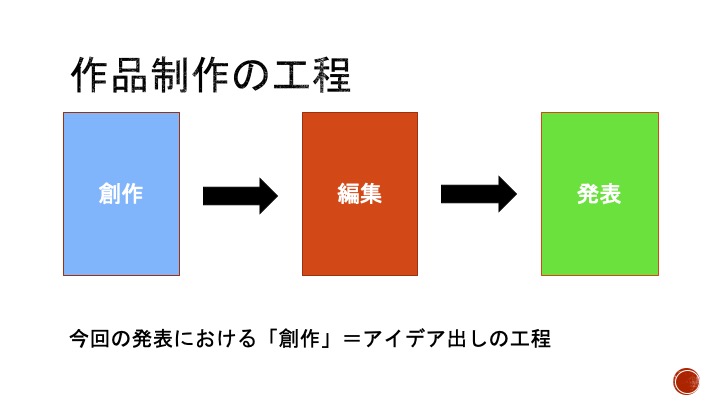
ここで、作品一般の創作の流れを仮に「創作」→「編集」→「発表」とします。
音楽について当てはめてみると、「(作詞)作曲」→「編曲」→「演奏・音源配信など」となります。
すでに、この各段階に関わるAIサービスが存在しており、以下のようなものがあります。
ジャンル、曲の雰囲気、長さを指定することで、楽曲が自動生成される。
BGMを作るのに向いており、大手通信社ロイターのサービスにも採用された。
日本語による自然言語処理技術を音楽に応用した機械学習アルゴリズム群を利用した自動作曲AI。
iOSのスマホアプリとして提供されており、アプリ版では、歴史上のヒット曲600曲をAIに学習・分析させたデータベースを使い、メロディに特徴量を付与して生成している。
ローマ教皇の来日イベントである「POPE IN JAPAN 2019」のオフィシャルテーマソング「PROTECT ALL LIFE 〜 時のしるし 〜」の作曲にも使われた。
専用キーボードもしくはコンソールによってメロディを入力し、ジャンルを選択すると、事前トレーニング済みモデルによって自動で編曲してくれるAI(作曲ではない)。
GANを使って伴奏を生成し、独自のモデルを作成することもできる。
楽曲制作のほか、AWS DeepComposerを通して機械学習について学習する「ラーニングカプセル」というサービスも提供している。
Music Trainsformerとは、Google社が開発した、MIDIデータ(音楽の演奏情報をデータ化したもの)を生成するAIです。
RNNを用いないSelf-Attention の導入により圧倒的な性能を見せた、自然言語処理AIであるTransformer(google翻訳に使われている)が先行しています。
Transformerとは要するに、「過去の自然言語処理(NLP)で多く使われる再帰型ニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)を 「Self-Attention Layer」に入れ替えたモデル」です。
RNNの中で使われる、過去の重要な点に着目するための手法で、各隠れ層を重み付けする。
context vectorによって重み付けすることで、各単語が参照すべき重要な単語を見分けることで、 説明可能なAIを作成する。(AIがどこに注意したのか可視化できるため)
時系列データを扱うニューラルネットワークであり、前の単語から抽出された重みを次の単語に引き継ぐ構造になっている。
前後のデータに関係性がある時系列データを分析するのに適す。
Transformerを使って、与えられたMIDIデータから、その先に来るMIDIデータを予測、作曲していくことができます。
音楽には小節という繰り返し構造や、モチーフを再利用することがありますが、 Transformerは直前だけではなく、長いスパンでの参照も可能であるため、より音楽らしいデータを作ることができます。
最後に、社員によるAIの作曲についての考察が紹介されました。
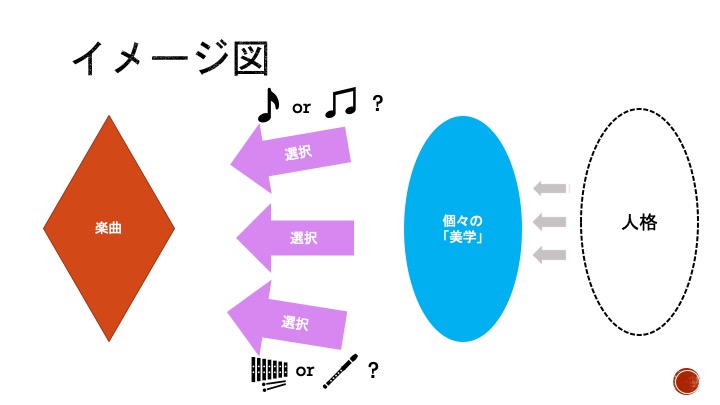
ちなみに、現状ではAIはある美学を持つ個人(あるいは集団)のデータを学習することによって、データ元の「美学」を再現することが可能になっています(AIが作ったビートルズ風の楽曲など)。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。