今回の勉強会のテーマは強化学習とEChartsでした。
強化学習は機械学習のジャンルの一つで、EChartsは多様なチャートを描くことができます。
それぞれ異なるテーマなので、一つ一つ解説していきます。
強化学習とは
強化学習は次のような学習手法です。
報酬を最大化するように、
行動を学習することです。
では、この
報酬や
行動とは、どのようなものなのでしょうか?
以下で、弊社のエンジニアが作成した
真っ赤な
りんごの様な色をしたジ
オメトリックな物体(以下、マリオ)を通して、
報酬、
行動、
強化学習について解説しようと思います。

テレッテッテテッテーテンッ♪
報酬と行動
まずは
報酬について考えてみようと思います。
一般に報酬は、「対象の目的を数量で表現したもの」になります。
このことを念頭に置いてマリオの報酬を考えます。
マリオは画面右側にある目的地を目指しているとします。
なので、言い方を変えると、マリオは出発点から離れることで目的を達成できます。
これを数量的に表現しようとすると、
「マリオは出発点からの距離(x軸の正の方向)が大きければ、大きいほど目的地に近くなる。」
になります。
つまり報酬は次のようになります。
報酬:マリオの出発点からの距離(x軸の正の方向)
次に、
行動について考えます。
行動は文字通りでOKで、「対象の行動を数量で表現したもの」になります。
未学習のマリオは右、左をランダムに進むので、これを数量的に表現すると「右、左を選択する割合」になります。
つまり行動は次のようになります。
行動:マリオが右、左を選択する割合
学習結果
冒頭で記述したように、強化学習とは
報酬を最大化するように、
行動を学習することです。
今回の報酬と行動をそのまま当てはめれば、次のようになります。
「マリオの出発点からの距離(x軸の正の方向)」を最大化するように、「マリオが右、左を選択する割合」を学習する
となります。
マリオは一定時間の経過した後の距離、もしくは、落ちた地点の距離の分だけ報酬を得て、それまでの行動を学習するので、
良い結果(出発点からの距離が大きい)や悪い結果(出発点からの距離が小さい)から、右、左を選択する最適な割合を学習していきます。
人間も同じですよね
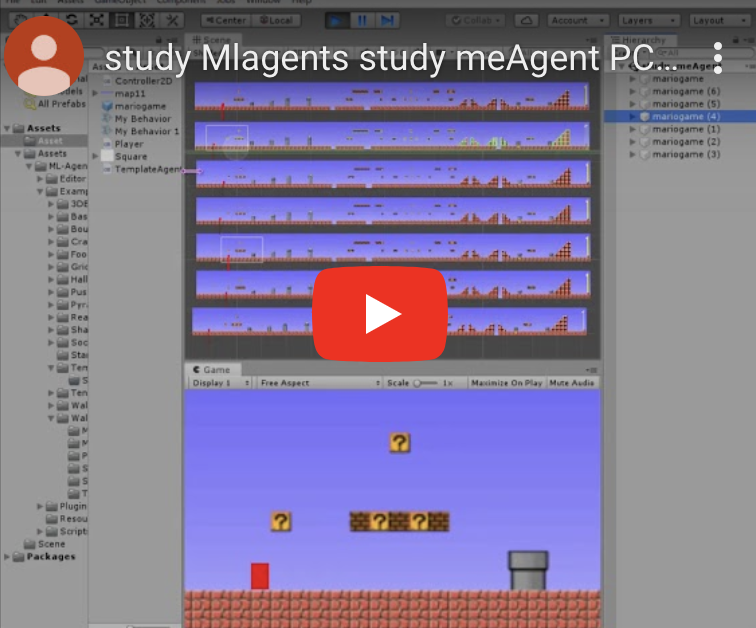
次の動画は学習初期の段階です。
学習初期では、右、左を選択する割合はほぼ1対1で、どちらに進めば良いか学習できていない状況です。

この段階は、右も左もわかっていない段階です。
なので、あまり前に進んでくれません。
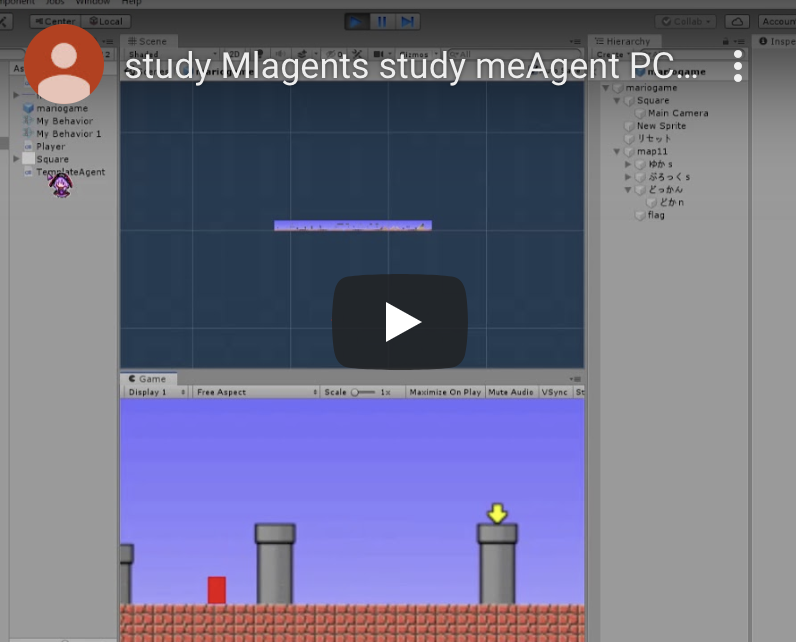
ある程度の学習を経て、最終的には、マリオは次のような行動をとります。

学習初期と比較すると、目的地にだいぶ近づけるようになりました。
ちなみに土管の当たり判定とジャンプは次回実装予定とのことでした。
Echarts
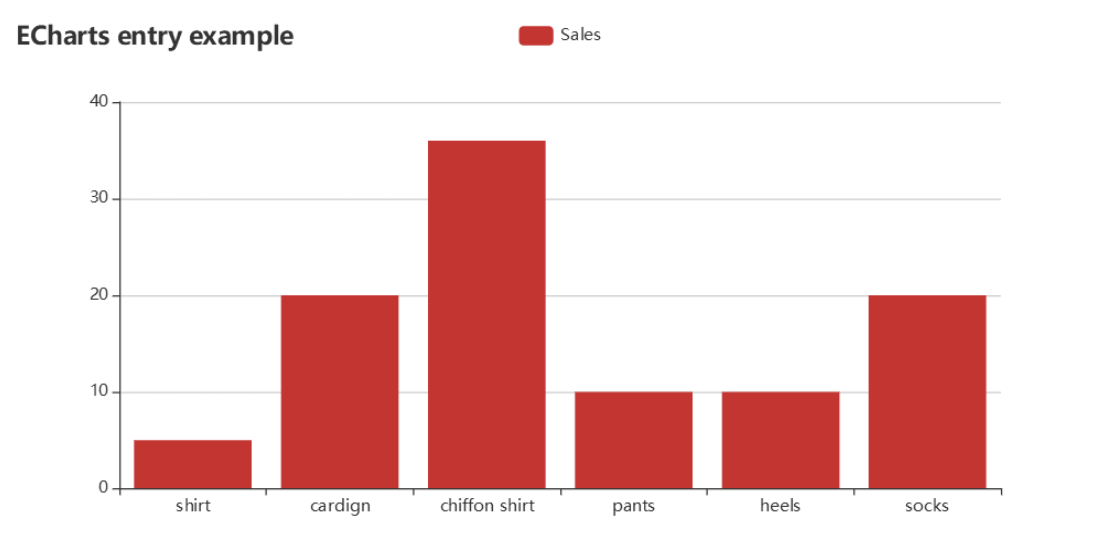
EchartはBaiduが提供しているHTML5/JavaScript製のオープンソース・ソフトウェア(MIT License)で、
多様なチャートを描くことができます。

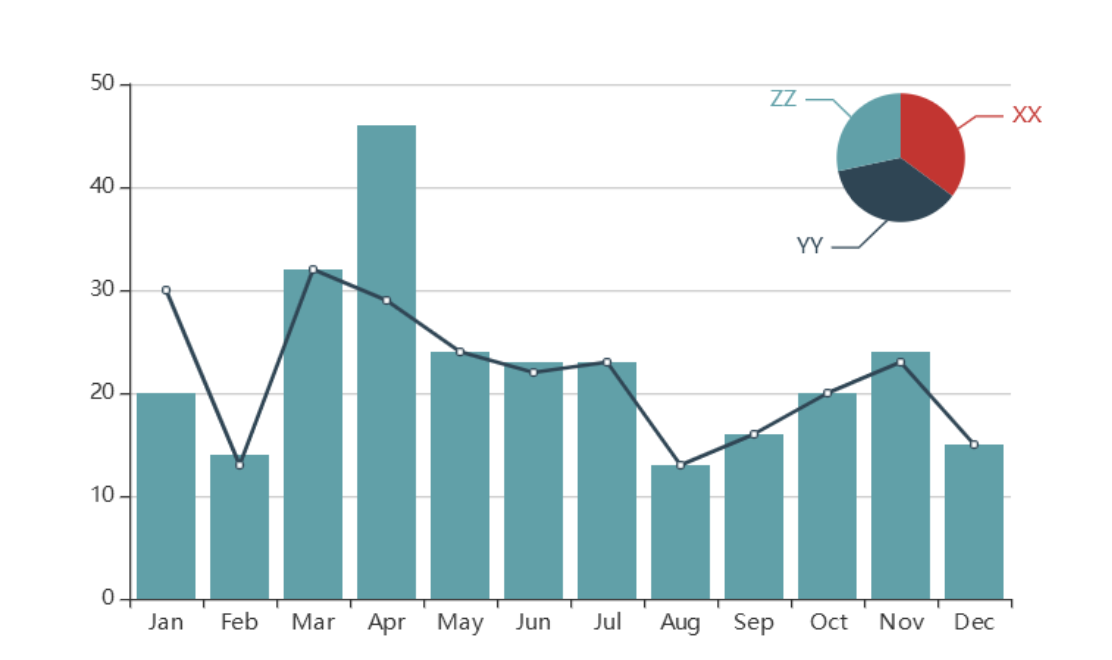
基本的な棒グラフから複数のグラフを組み合わせたグラフも

上記以外にも多様なテンプレが用意されているので、目的のチャートが見つかるかも?!
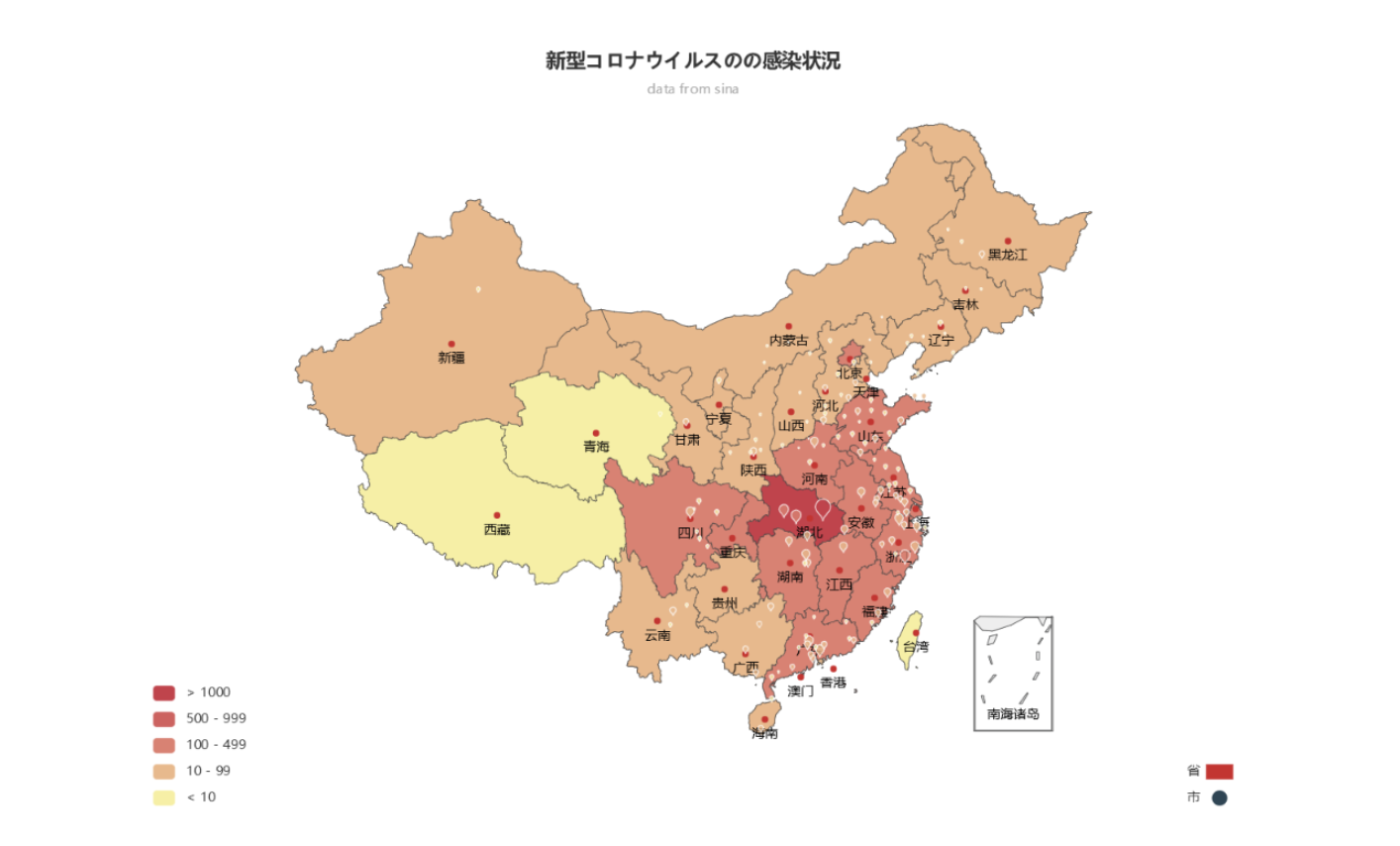
弊社のエンジニアは、このEcharstを使って、新型コロナウイルスの感染状況のチャートを作成しました。(2020年1月末)

現在の状況は
ここから確認できます。
次は是非日本版を作成してもらいたいですね!(真っ赤ではないことを祈るばかりです。)