2024年12月10日
こんにちは、こちらはまたAI/BI部のLになります。
正直うまく書ける自信があまりないですが、今回の記事は、自分の視点で生成AIがトランスフォーマーを中心とする時代までの経緯を語りたいと思います。
「注目!」
ちょうどその意味があるのでお借りさせていただきます。
Wikipediaによると、「生理学において注意とは脳が多数の情報の中から認知すべき情報を選択する機能のことである」。
まるで現代科学の起源はいつもオカルトから離れられないように、嘗て、スピリチュアル心理学が流行っていて、脳を神秘化する時期がありました。
(率直に言えばヒッピーたちがユングやフロイトなどからパクって作ったスピリチュアル理論です。もうゲームや文芸作品のネタになってしまったのは幸いでした。)
そんな時期に、結合主義の下で、多層パーセプトロン、さらにCNNs(畳み込みニューラルネットワーク)と誤差逆伝播法の雛形も誕生しましたが、それもコンピュータの計算能力がまだ足りない、GPUさえも誕生していない時代なので、一時的に、そういう手法は停滞に落ちました。
代わりに、よく主観タスクに使われたのは手作りの特徴(hand-crafted feature)でした。
主観タスクとは、所謂「計測できない」誇り高きヒトの「感情」や「精神」に結果が左右されるタスクです。もちろん、現代でも、医療や芸術に関するAIタスクは主観評価実験は欠かせないけれども、昔は、よく手作りの特徴を使いながら、心理学や認知科学から根拠を見つけようとするため、主観タスクが似て非なる認知科学の実装になりました。
そんな中、「注意」に目を付けたタスクは、顕著性マップの作成でした。顕著性マップとは,人が視覚情報の中に特に注目しやすい部分を示したものです。(参考: https://en.wikipedia.org/wiki/Saliency_map)手法を探すのにも、心理学や認知科学の仮説を参照することが多いでした。ですが、それらの仮説が当時の画像処理手法で実装できない、または仮説自体が普遍性を欠けた可能性もあるため、実用上に困難をもたらしました。
現在よく「Attention」と呼ばれるものは、実はすべての入力情報を統合する機構です。といっても、「別にスペクトログラムでもグローバル情報じゃない?」と考えられるが、「Attention」の前身の一つである「non-local」手法は、文脈的に、フィルタ処理の分枝から生えたものでした。localとは、「パターン枠くん」(フィルタ、カーネル、トークンなど)が建物の各部屋の中に自分の仲間を探し出せるが、建物全体の仲間分布がわからないことです。ゆえに、「non-local」は建物の仕組みまで砕いて統計することではなく、各部屋の情報からさらに分析する方針です。
とはいえ、また計算能力が足りないという話に戻ったが、前世紀末に「non-local」を実装するのも難しいですね。
顕著性マップとほぼ同時期に、HMM(隠れマルコフモデル)という手法があります。昔はHMMとHMMしかやらない日々でしたと、ある教授からそういう昔話を聞いたことがあります。多分その前にすでにマルコフの理論に基づいた手法はたくさんあったが、HMMはマイルストーンであるため、広く使われていました。
この「HMM」は、実は生成モデルです。実際動いている様子を見ると単なる「一つのものから関連している別のものに転移する」に見えます。つまり、「パターン枠くん」は建物に入ることすらしなかったのです。ですが、組み立てたものは結果的に「新しいデータ」だから、生成モデルと見なされます。詳細はまたWikiに参考してください。(https://ja.wikipedia.org/wiki/%E9%9A%A0%E3%82%8C%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E3%83%A2%E3%83%87%E3%83%AB)
現代の生成モデルの起源には、HMMのタスクを受け継いだRNNs(回帰型ニューラルネットワーク)のEncoder-DecoderとCNNsの反攻で生まれたVAE(変分オートエンコーダー)があります。ここまで話すと、すでにニューラルネットワークを避けられないので、まずニューラルネットワークを簡単に説明します。
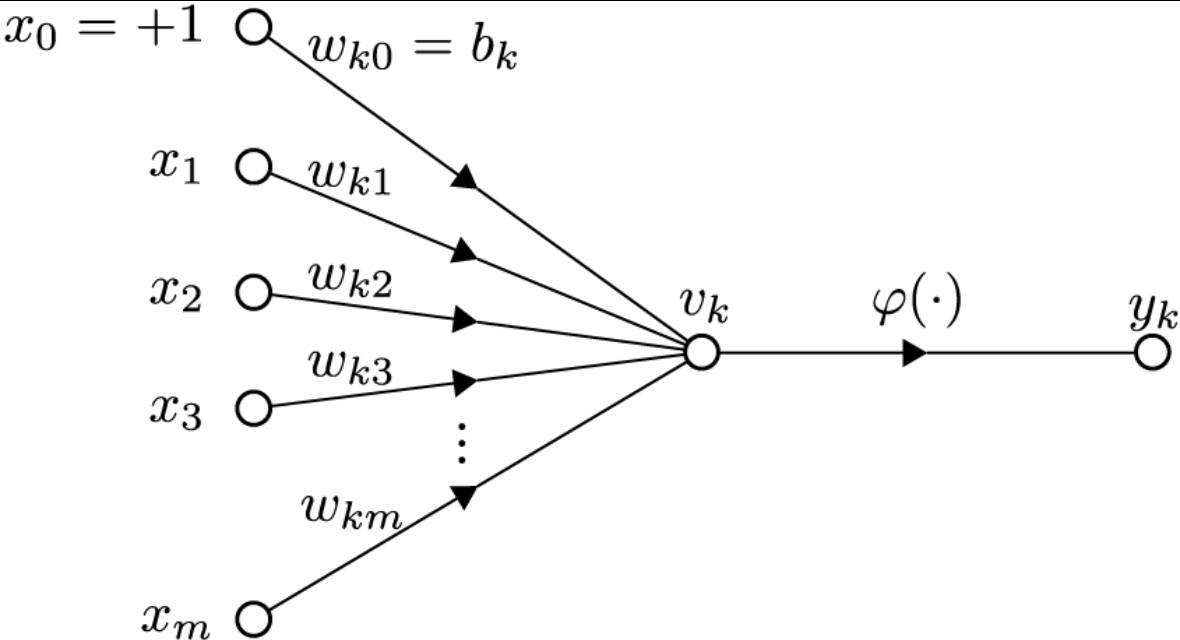
上記のWikiニューロン図が示したように、パーセプトロンは神経細胞の活性化仕組みを模倣してできたネットワークです。Universal Approximation Theorem(普遍性定理?)によると、input、hidden、output層を持つパーセプトロンは、無限のhiddenニューロンさえあれば、すべての関数に近似できます。即ち、前状態「入力」と後状態「出力」さえあれば、なんでも近似できます。
ちなみに、ラプラスの悪魔という話もありました。全く現実世界に適用できる理論ではないですが、うまくモデリングできれば、世間のすべてを「前状態」と「後状態」に定義して近似できることを示唆しているのではないでしょうか。https://ja.wikipedia.org/wiki/%E3%83%A9%E3%83%97%E3%83%A9%E3%82%B9%E3%81%AE%E6%82%AA%E9%AD%94
また、「無限のhiddenニューロン」は事実上に実現できないので、ネットワークのhidden層をたくさん増やし、「無限のhiddenニューロン」と同型のようにするのが、「深層学習」です。普通なら、これに関して多少疑問があると思いますが、そんな時は、複数のrelu関数ニューロンを合成したり組み合わせたりいろんな曲線を描いてみましょう。そしてなぜ同型のようにできるかは多少感じられるはずです。(今の時代では自分で描かなくてもchatgptに聞いたら出せます)下図も似たような例です:“With four parameters I can fit an elephant, and with five I can make him wiggle his trunk.”
現代の生成モデルは、主にノイズや特徴コードからテキスト、音声、画像などを生成することを行います。Encoder-DecoderとVAEは違う分野にありますが、原理は似ています。
Encoderは元情報から始め、層ごとの特徴を組み合わせてより複雑な特徴を抽出します。ゆえに、誤差の逆伝播によって、情報の特徴は自動的に特定のノイズやコードに結びつくことができます。Decoderはノイズやコードから始め、層ごとのコードによって特徴を組み立てます。特徴自体は部品として扱われるので、当然、「データセットにない」組み合わせを出力できるのは可能になります。これが「生成AI」です。
つまりその過程は、現実世界の一部を取って(この文脈は上記のラプラスの悪魔を参照)、「このブラックボックスを潰して部品さえ取れば他のおもちゃも作れるね!」というアイデアです。ここに、「生成する」という役割を担うのは実質Decoderです。
実用上に近似できる関数の幅が広くなったが、深層学習も機械学習の一種です。だから同様に、問題を「どのようにモデリングするか」と「どのように最適化するか」に変換できます。それなら「学習」の本質はなんなのかという形而上学的な問題に拘らなくても、改善に向けて考えるようになったのではないかと思います。
Decoder生成法の後にあるマイルストーンは、GANs(敵対的生成ネットワーク)でした。個人的には、GANsが、結果の「出力」とノイズの「入力」さえあれば、逆伝播法でなんとかできることを証明しました。
余談ですが、当時の画像生成の研究はまた「GANsとGANsしかやらない」だったと言えます。その分野にやってることは、まさに今絵師さんたち(🙇🏼♀️🙇🏼♀️🙇🏼♀️)に強く叩かれている「スタイル変換」(CycleGANのアイデアは本当に精妙です!検索してください!見ても損はない!強くお勧め!)、「ヒト顔生成」、「Text2Image」などのタスクです。その時、AIの出力もそんなに良いと言えなかった一方、研究のためだけなら商業的な利益を生まないため、来歴がわかってもわからなくても、いろいろな画像がトレーニングの材料になりました。ですが、今後は規範化されるでしょう。
それでは、GANsの仕組みを簡単に説明します。まず、GANsの中に「生成する」という役割を担うのは「生成器」そのものです。生成された画像は直接的に元画像と差分を取ることではなく、元画像と一緒に「識別器」に入力されます。その後、「識別器」は頑張って生成画像と元画像を見分けて、「生成器」は頑張って区別しづらい画像を生成します。これによって、「生成器」と「識別器」は共にトレーニングされます。結果的に両方の精度も高くなれます。
こういう手法は「識別器」によってより本質的な特徴を取れる一方、対象物全体の構造やディテールも取れます。ゆえに、Decoder生成のように元画像との誤差を取る方法より、生成の安定性と多様性が確保できます。
上記はトランスフォーマーが誕生する前までの経緯でした。気づいた方もいると思いますが、その時期になれば、GPUの性能やアルゴリズムなどを含め、「non-local」を実現する条件はこっそりと集められました。画像分野のNon-local Neural Networks(https://arxiv.org/pdf/1711.07971)が出た数ヶ月前、後世に語り継がれる「Attention Is All You Need」(https://arxiv.org/pdf/1706.03762)は発表されました。この「Attention Is All You Need」の中に提出された深層学習モデルは、「トランスフォーマー」です。
![]()
上記の画像はDall-Eによって生成されたトランスフォーマーです。Attention機構を搭載したやつが出る前に、トランスフォーマーはそういうロボットを指すのが一般的でした。
個人的な意見ですが、トランスフォーマーの提出はどこかの天才が一時的にそういう発想があったことではなく、ゲーム開発のように、すでにみんなが綺麗なビジュアルをずっと入れたがっていて、ようやく強いグラフィックボードが発行されて、そういうゲームを作れるようになっただけだと思います。
そのものは人類の集合ができて、また集合としての人類の知恵を学べるようになってしまいました。
トランスフォーマーが誕生する前、実はいろんな形のAttentionやnon-localがすでに深層学習に適用されました。LSTM(長・短期記憶モデル)にはよくattentionというものが見られます。下記の手法を参照してください。(https://arxiv.org/pdf/1409.0473)(https://arxiv.org/pdf/1611.01603 )
Attentionを導入する理由もごく簡単です。最初は「倒置した表現は認識できないかも」に対して、文の先頭からも後尾からも、何回読んで解決します。その後、前後は覚えられるが、文章が長すぎると中間にある内容はよく忘れられるから、「fully-connected以外に全文から疎な意味情報を取れる方法があればいいね」という旨で、だんだん各種のAttentionが導入されました。最後に、自己回帰モデルが遅すぎて、並行処理できないから、いっそ自己回帰を捨てて、Attentionが「All You Need」になりました。
![]()
トランスフォーマーのコアな仕組みは上記の画像がすでに示したが、多分それだけで意味がわからないので、ちょっと詳しく説明します。
「Q@K@V」
正規化とsoftmaxを除いたが、上記のPython糖衣構文はAttention機構のコアです。初めてサンプルコードにこれを見た時、まるでこの「渦巻×2」だけで巨大な重機を動かしたという感じがありましたね。
なぜなら、GPUは普通に使われていますが、M2個のパッチがある画像における計算量はO(M4・N)となっています。Nはトークン情報の次元数で、普通でも1024があります。またMを16として、計算量が67108864となっています。これは一層だけで、実は普通に12層もあります。となると、計算量はAttentionだけでも805306368になります。ここに、もし画像じゃなくて、長文をカレント記憶として利用したい場合、M2を1024(トークン数)にしたら、計算量は1073741824までになれます。これが、これらの「渦巻」が動かしたものです。
この渦巻は何かというと、実は行列乗算です。Q、K、V自体は異なる変換行列で変換された入力で、つまりq(x)、k(x)とv(x)です。トレーニングする中で、QKVがxに対して以下の行為を行うまで組織化されます(式の方を見たい方は下記の式を参照してください):
1.xくんが自分のタイプに変換される
2.xくんが自分と似ている仲間を探し出す
3.仲間が多くなればなるほどxくんが強化される
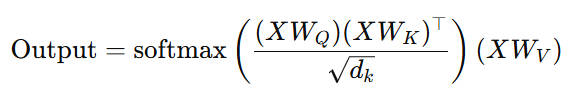
これが終われば話が早いですね。残りは、FFN(Feed Forward Network)というパーセプトロンと、多様性を保証するために複数のAttentionを行う「Multi-Head Attention」ですね。それらを加えれば一つのトランスフォーマー層でした。このようなトランスフォーマー層を畳めば、最後のトランスフォーマーになります。もちろん、「cross-attention」などの仕組みもあるが、それはバニラバージョンのgptに使われないので、詳細を割愛します(来週はあるかも😊)。最後に、またHMMの生成方式をトランスフォーマーに適用すれば、openaiが使っているgpt型のLLMができました。
今回の記事は生成AIがトランスフォーマーを中心とする時代までの経緯を書いてみました。さすがに文字数や時間に限界があるので、多分漏れたことも多いですが、これを最後まで書けるのは良かったと思います。
今回のアドベントブログに、来週は僕の最後の記事ですね。また来週。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。