こんにちは、新入社員のS・Kです。
今回は、AIによる動画生成の最新動向をまとめた論文 A Survey on Physical Understanding in AI-based Video Generation をもとに、AIがどのように「物理的に正しい世界」を理解・再現しようとしているのかを紹介します。
原文では、AIによる動画生成の中で「物理」がどのように取り入れられ、発展してきたかについて、さまざまな新しい方向性や改良手法が詳しく整理されています。
ここでは紙幅の都合上、その核心部分のみを簡単に紹介します。より詳しい内容は原文をご覧ください。
第1章 序論(Introduction)
近年、Sora、Kling、HunyuanVideo などの動画生成モデルは、視覚品質、時間的一貫性、テキスト指示への追従性などの面で著しい進歩を遂げています。これらはゲーム、ロボティクス、自動運転、科学研究など多様な分野に応用が広がり、Instruction-tuning、In-context learning、プランニング、強化学習などの技術とも組み合わさり、汎用人工知能(AGI)に向けた重要な構成要素と見なされています。
しかし、複雑な動的シーンでは「見た目はリアルでも、物理的には正しくない」現象が頻繁に発生します。例えば、ニュートン力学や運動量・エネルギー保存則に反する挙動などです。これらの問題は、ロボティクスや自動運転のような実世界応用において深刻な影響を及ぼしかねません。
著者らはピアジェの認知発達理論に着想を得て、AIの物理理解を以下の三層構造で整理しています。
🔹 基本的スキーマ的知覚による生成(Basic Schematic Perception):低忠実度の視覚パターンや運動刺激をもとに、直感的に動画を生成する段階
🔹 受動的物理認知による生成(Passive Cognition):物理シミュレータや大規模言語モデル(LLM)に内在する物理知識を生成モデルに統合する段階
🔹 能動的世界シミュレーション(Active Cognition):環境との相互作用を通じて因果関係を理解し、物理的に正しい未来を予測する段階
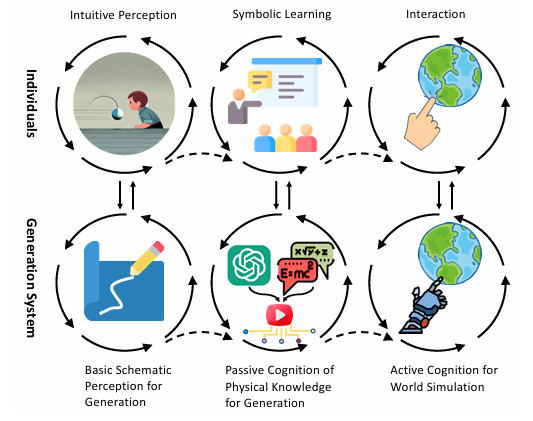
図1 個体および生成システムの認知進化過程
本論文は、第3章で背景(物理常識、主流生成モデル、物理シミュレーション)を説明し、第4〜6章でこの三層を軸にした生成手法を解説し、第7章で評価基準とベンチマーク、第8章で課題と展望、第9章で結論をまとめています。
第2章 調査範囲と比較(Scope & Comparison)
本研究の焦点は、物理的忠実度を備えた動画生成です。すなわち、2D動画、動的3D、そして4D生成を含み、視覚的リアリティだけでなく運動学・動力学・光学といった物理法則との整合性を重視しています。
対象外とされている領域:
・無条件動画生成や長尺動画生成
・物理的先験や運動要素を伴わない純粋な視覚変換(例:スタイル転送、超解像など)
従来の多くの研究が「明示的シミュレーション vs 暗黙的学習」や「3D/4D中心の分類」に依存していたのに対し、本論文は人間の物理領域における認知発達プロセスをもとに生成技術を整理している点で独自性があります。これにより、物理的整合性を備えた生成モデルの設計や、認知科学とAGIの融合を導く新しい視点を提供しています。
第3章 背景(Background)
3.1 物理的常識(Physical Commonsense)
著者は「物理常識」「物理法則」「物理現象」を次のように定義しています。
・物理常識:人が日常的に持つ直感的理解(例:重い物体は落ちる)。
・物理法則:自然界の普遍的ルール(例:運動量保存則、重力)。
・物理現象:それらの法則が相互作用した結果として観測される出来事。
物理常識は以下の4分野に整理され、PhyGenBenchで27の基本法則がカバーされています。
・力学(摩擦により車が停止するなど)
・光学(鏡における光の反射など)
・熱学(熱伝導など)
・材料特性(塩は水に溶ける、油は水に溶けないなど)
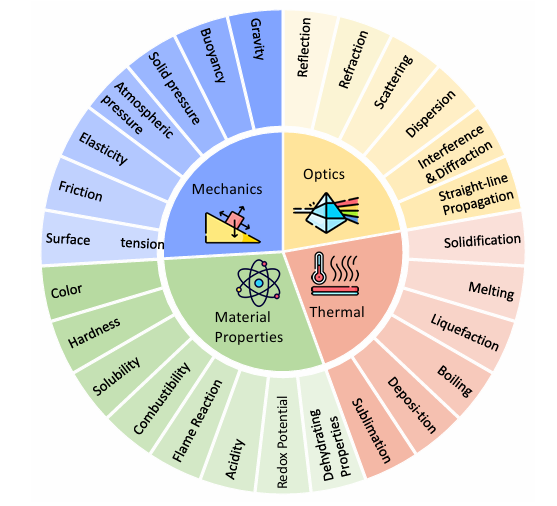
図2 PhysGenBenchベンチマークにおける分類(4つの物理的常識と27の物理法則を含む)
3.2 主流の生成モデル(Generative Models)
・GAN(Generative Adversarial Network):生成器と識別器を対立的に学習させ、高忠実度なデータを生成します。
・Diffusion Model(拡散モデル):ノイズ付与と除去の反復過程を学習し、安定した高品質生成を実現します。
・NeRF(Neural Radiance Fields):空間座標と視線方向を入力とする連続関数を学習し、体積レンダリングにより任意視点の画像を合成します。
・Gaussian Splatting(3DGS):各向異性3Dガウスでシーンを表現し、透明度・深度を重みとして投影・加算します。時間軸を導入して4D動画生成にも対応します。
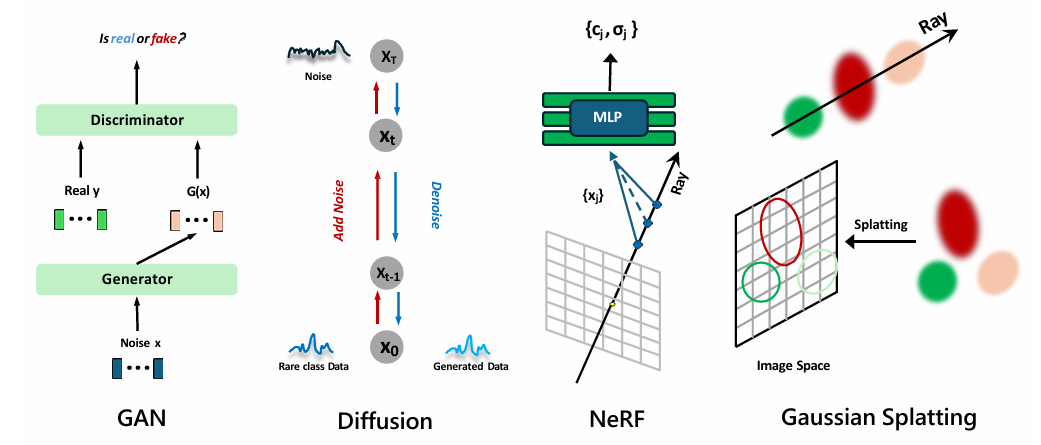
図3 主流の生成モデルの概要(GAN、Diffusion Model、NeRF、Gaussian Splatting)
3.3 物理シミュレーションとプラットフォーム(Physics Simulation & Platforms)
・PBD(Position-Based Dynamics):位置制約に基づく安定なリアルタイムシミュレーションで、布や柔体などに適用されます。
・XPBD(Extended PBD):PBDの時間ステップ依存や剛性問題を改善し、より正確な物理挙動を再現可能にします。
・MPM(Material Point Method):ラグランジュ粒子とオイラー格子を組み合わせたハイブリッド方式で、弾性体・流体・粒子を高精度に表現でき、ニューラルネットとの統合も容易です。
代表的な環境:Bullet / PyBullet、Blender、Isaac Gym、NVIDIA PhysX、Taichi、Omniverse、Genesis です。
第4章 基本的スキーマ的知覚による生成(Basic Schematic Perception)
AIが動画生成において「現実の物体のように動く」ことを学習する方法が探究されています。初期のモデルは既存の動画から光フローやモーションベクトルを抽出し、画面上の運動パターンを模倣することで動きの一貫性を実現していました。近年は、参照動画から運動方向・速度分布・ポーズ遷移などの属性を取り出し、テキスト/画像プロンプトがもつ外観や配置の先験と組み合わせる「V2V(Video-guided)」系のアプローチが主流になっています。
例として、外観と運動の絡み合いをほどいて時間的一貫性を強化する手法(VMC、MotionDirector)、光フローに加えて深度を条件信号として用いて空間整合性を高める手法(FlowVid)、周波数領域の整合で局所歪みを抑える手法(SMA)などが提案されています。これらは、参照動画の運動パターンを抽出 → 潜在空間に埋め込み → 生成フレームに伝搬、という流れでモーション整合を高めます。
研究が進むにつれて、物体の軌跡やカメラの動きを明示的に制御する「Motion-guided」系が登場し、単段(エンドツーエンド)/二段(運動表現抽出→拡散モデル注入)の2パラダイムで発展しています。具体的には、点群軌跡・バウンディングボックス・光フローなどの低次元運動表現をControlNet風ブランチや時間注意で潜在に注入し、2D点での物体移動や3D軌跡でのカメラ制御を両立させます(Dragnuwa、VideoComposer、MotionCtrl、Motion-I2V、DreamVideo-2、Tora、AnimateAnything、Direct-a-Video、Image Conductorなど)。
一方で、3D空間での物理的運動(奥行き変位・遮蔽・回転/軌道運動)を扱うため、深度とクラスタリングを併用して3D軌跡を制御する方法や、LLMでテキストから3D軌跡を導出する方法、3D軌跡データセットと埋め込みモジュールで6DoF制御を可能にする方法(LeviTor、C3V、3DTrajMaster)も現れています。また、多物体が接近・衝突する際に軌跡が混線する問題に対しては、IDマップや相互作用事前を導入して安定化する工夫(InTraGenなど)も提案されています。
加えて、深度・照明といった物理的信号を生成過程に組み込むことで、立体感やライティング整合を高める試み(GenLit、LumiSculpt、HDRマップを埋め込み化して制御する手法)や、学習済み拡散モデルの潜在運動を追加学習なしで引き出すゼロショット自己誘導(Motion Modes、SG-I2V)も示されています。
これらの方法は映像の時間的・空間的一貫性を大きく高め、「より自然な」動きを再現することに成功していますが、依然として重力・衝突・保存則といった物理法則の厳密な順守までは保証しづらい側面があります。この「視覚的リアリズムから物理的リアリズムへの移行」を補うために、第5章では物理正則化やシミュレータ統合、LLMの物理知識といった“受動的物理認知”の枠組みを扱います。
第5章 物理に着想を得た・物理に基づく生成(Physics-inspired & Physics-driven Generation)
動画生成モデルを「見た目のリアリティ」から「物理的な正しさ」へと発展させるため、研究者たちは物理法則を明示的に導入しています。 本章は、(1)物理正則化(損失関数に物理拘束を入れて一貫性を高める)、(2)物理シミュレーション統合(シミュレータの出力を生成の条件・監督に用いる)、 (3)マテリアル空間の推定(材料パラメータや構成則を学習して現象の再現性を上げる)、(4)LLMを用いた物理知識の補強、の四つの柱で整理されています。
🔹 物理正則化(Physics-inspired Regularization):運動量保存・エネルギー保存・局所剛体性などの制約を損失に組み込み、学習を通じて破綻しにくい運動や形状を獲得します。GauSimは連続体力学の階層シミュレーションと質量・運動量保存の制約を併用し、DeformGSは局所等長・運動量正則化で大変形時の軌跡平滑化を図ります。Dynamic 3D Gaussiansは局所剛体・回転一貫性・長期等長の損失で6DoF追跡を安定化します。
🔹 物理シミュレーション統合(Physics Simulation-based Generation):MPM/PBD/XPBD/NeRF統合などで外力入力→物理進化→レンダリングを一気通貫に行い、相互作用を物理的に整合させます。3DGSとMPMを結合したPhysGaussian、XPBDを使ったVR-GS、NeRFと古典力学を融合するPIE-NeRFなどが代表です。また、生成前段でシミュレータにより運動場(光フロー・深度・境界等)を物理一貫に作り、そのまま条件入力にするMotionCraft/PhysAnimator/GPT4Motion/PhysGenの系統もあります。
まず5.1 物理正則化では、データ駆動の拡散モデルに物理量の拘束を加える設計が解説されています。質量・運動量・エネルギー保存、長さ・面積保持(ARAP/LA)、局所剛体性などを損失に入れることで、フレーム間の速度・加速度・回転の一貫性や、変形体の形状保持を改善します。 これにより視覚的破綻(めり込み、局所ねじれ、非物理的な振る舞い)が減少し、長時間の運動でも破綻しにくくなります。ただし、未学習の相互作用や複雑現象まで保証するわけではないため、次節の明示シミュレーションの併用が重要になります。
5.2 物理シミュレーション統合は二系統に分かれます。 ひとつ目はインタラクティブ動力学生成(5.2.1)で、静的3Dシーンに外力や境界条件を与え、MPM/PBD/XPBD/NeRFなどの物理エンジンを通じて因果的に時系列を進めた後、レンダリングを行う手法です。
代表例として、PhysGaussianは3DGSの各ガウスを粒子として扱い、MPMと連結して外力・衝突・変形を統一的に表現します。 VR-GSはXPBDを導入して安定性とリアルタイム性を両立し、Gaussian SplashingはPBDで固体・流体の相互作用を統合し、反射や鏡面効果にも対応します。 NeRF系では、PIE-NeRFがメッシュレス構造で大変形に対応し、Video2GameはNeRFをベースにシーンをゲームエンジン互換の3D世界として再構築します。
ふたつ目は運動場の物理化(5.2.2)です。これは生成前にシミュレーションを用いて、物理的に整合する光フロー・深度・輪郭などの条件を作り出し、それをControlNetや拡散モデルの入力条件として利用する方法です。
MotionCraft、PhysAnimator、GPT4Motion、PhysGenなどが代表であり、いずれも「シミュレーションで得た運動場を条件信号として利用する」点に特徴があります。 これにより、従来の「手書き軌跡」よりも信頼性の高いモーション制御が可能となり、生成映像の物理的一貫性を大きく向上させています。
Sim2Realギャップへの対処: シミュレータ条件と現実条件のズレを埋めるため、SimGenは「シミュレータ→軽量拡散で現実的条件に変換→本生成」という段階的フローを採用し、実写感と物理一貫性の両立を図ります。
ニューラルPDE連携: ElastoGenのようにPDEの数値解を学習過程に組み込み、ネットワーク自体に物理の解探索を担わせる流れも示されています。
5.3 マテリアル空間のシミュレーションでは、ヤング率・ポアソン比・粘塑性などの材料パラメータや構成則を推定・学習して、現実的な変形・流動・接触を再現する試みがまとめられています。 PhysDreamerはMPMと組み合わせ、2D拡散モデルのスコアを利用して3D構造を最適化する手法「Score Distillation Sampling(SDS, DreamFusionで提案)」を採用し、動画中の物体変形を物理的に整合させます。 PAC-NeRFは粒子とグリッドのハイブリッド表現を導入し、動的物体の幾何と物理パラメータを動画から監督的に推定します。 Physics3DはMPMを拡張し、弾性・粘性を同時に扱うことで粘弾性体の挙動をより正確に再現します。
さらに、DreamPhysicsはSDSを拡張し、運動情報を強調する「Motion Distillation Sampling(MDS)」を提案しています。これにより、2D拡散モデルの知識を用いて3D/4Dの物理場を逆推定し、時間的一貫性(temporal consistency)を向上させます。 OmniPhysGSは構成則そのものを学習可能にし、さまざまな材料特性に柔軟に適応します。 NeuMAは既存の専門モデルとの差分を学習し、実際のダイナミクスに対して残差補正を行います。
また、SDSによる最適化は高精度である一方で計算コストが大きいため、光フロー損失などを利用してより軽量に材料推定を行う手法も提案されています。 これらの研究により、材料の多様性を考慮した高精度な物理再現と、学習効率の両立が進められています。
この節の要点: PhysDreamerはSDSで動画から物理場を蒸留し、PAC-NeRFとPhysics3DはMPMを基盤に物理パラメータを高精度に推定します。DreamPhysicsはSDSを拡張してMDSを提案し、時間的一貫性を強化しました。OmniPhysGSは構成則の直接学習、NeuMAは残差補正により現実ダイナミクスへの適応を向上させています。これらにより、物理的整合性と効率性を両立したマテリアル生成の新たな方向性が示されています。
5.4 LLMによる物理推論の補強では、LLMが持つ世界知識を利用して、シーンレイアウトの組み立て、スクリプト生成、物性推定(密度・弾性など)を支援する方向性が示されています。 これにより、記号的知識と連続物理のブリッジが強化され、テキスト→物理条件→動画の一貫した生成がしやすくなります。
この章の要点: ① 損失への物理拘束で破綻を抑制、② シミュレータ統合や運動場の物理化で因果的・相互作用的な動きを再現、③ 材料・構成則の学習で現実の多様材に対応、④ LLMで記号知識を補いパイプライン全体の整合を高めます。これらにより、生成は「単なる再現」から「物理的整合性を伴う生成」へと前進します。
以上により、第5章は「視覚的リアリズム」から「物理的リアリズム」への要となる設計群を体系化し、 評価・限界・今後の方向性(シミュレータ精度、Sim2Real、計算コスト、材料多様性、LLM連携)を明確にしています。
第6章 世界モデルと能動的シミュレーション(World Modeling & Active Simulation)
AIが「見る」だけでなく「理解し、行動する」ことを目指す研究が進んでいます。本章では、環境の状態を内部に表現し、将来の変化を予測・計画する世界モデルの枠組みを軸に、能動的な相互作用を通じて物理的一貫性を高める方法を整理しています。具体的には、(1)マルチモーダルデータ駆動、(2)空間環境認識、(3)外部フィードバック最適化、の三つの流れで最新動向をまとめています。
🔹 6.1 マルチモーダル・データ駆動型生成:大規模動画拡散やワールドモデル系の学習(例:Sora、Genie、UniSim、WorldDreamer、DriveDreamer、GAIA-1、Cosmos)を通じて、テキスト・画像・動画・センサ情報を統合し、将来フレームや行動を予測します。学習済み表現を活用して、外力やユーザー操作に応じたリアルタイムな更新も可能にします。
🔹 6.2 空間環境認識:3D表現(NeRF/3DGS)やマップ・オブジェクトレベルのレイアウトを内部に取り込み、カメラ運動・物体運動・遮蔽などの空間的制約を扱います(例:ManiGaussian、DrivePhysica、DreMas、DriveDreamer4D など)。これにより、シーン理解と運動計画を結びつけ、物理的にもっともらしい未来予測を実現します。
🔹 6.3 外部フィードバック最適化:報酬モデルや外部エージェントからの評価信号を用いて生成を改善します(例:IPO、VideoReward、VideoAgent、Gen-Drive、PhyT2V など)。環境との反復的な相互作用により、長期整合・安全性・目標到達性を高めます。
まず6.1では、動画拡散モデルやワールドモデルを用いて、過去の観測から将来の状態と行動を予測する枠組みを示しています。テキストや画像に加えて、深度・光フロー・センサ列などの信号を組み合わせ、予測の安定性と一貫性を高めます。これらのモデルは、学習済みの時間表現と物理的常識を間接的に獲得しており、プロンプト追従と動的一貫性を両立させながら、インタラクティブな生成にも発展しつつあります。
次に6.2では、世界モデルに必要な「空間の土台」を強化します。具体的には、3D表現やシーンレイアウト、可動体のトポロジ、運動拘束(剛体性・接触・遮蔽)を中間表現として保持し、予測時にカメラ・物体・背景の整合を保ちます。これにより、走行シーンやロボット操作などで、物理的にあり得る軌跡と視覚的整合(マスク・深度・エッジ等)を同時に満たす生成がしやすくなります。
さらに6.3では、外部フィードバックの導入により「行動の良さ」を定量化して生成を最適化します。報酬学習や評価器を組み合わせ、長期的整合(目標達成・衝突回避・エネルギー節約など)の観点でサンプルを改善します。エージェントが環境から得た観測と報酬を反復利用することで、単なる視覚模倣から、実用的な行動計画・意思決定に接続することを目指します。
この章の要点: ① マルチモーダル表現で将来を予測し、入力操作や外力に応じて動画を更新します。② 空間環境認識により、カメラ・物体・遮蔽・接触の整合を保った3D一貫性を確保します。③ 外部フィードバックで長期的な行動品質を最適化し、世界モデルを「理解して行動する」体系へ前進させます。これらにより、AIによる動画生成は「世界の模倣」から「世界の創造・運用」へと段階的に移行します。
総じて第6章は、能動的相互作用と内部状態表現を備えた世界モデルの設計指針を示し、物理的一貫性・空間的整合・長期目的最適化を同時に満たす方向性を明確にしています。
第7章 物理的一貫性の評価とベンチマーク(Evaluation & Benchmarking)
AIが生成した動画が「物理的に正しい」かを検証するため、複数の評価指標が提案されています。評価はおおまかに、視覚的一貫性・物理量的整合・物理推論能力の三観点に整理されます。
🔹 視覚的評価: 動作の滑らかさ、影の整合性、オブジェクトのめり込みの有無などを、人間による主観評価または自動スコアで測定します。
🔹 物理量評価: 運動量保存・エネルギー平衡・重力加速度の一致度などを定量化し、現実法則との誤差を算出します。
🔹 物理推論タスク: 積み木崩壊、液体溢出、物体落下などの現象を予測・再現し、AIが「なぜ動くか」を理解できているかを検証します。
さらに、生成過程そのものが物理法則に従っているかを測る新指標として、Physics Consistency Score(PCS)などの自動評価手法も登場しています。 一方で、人間の直感に基づく主観評価も依然として不可欠であり、両者を組み合わせた多面的評価が主流となりつつあります。
代表的なベンチマークPhyGenBenchは、力学・光学・熱・材料の4領域を包含し、27の物理法則を網羅します。 近年では「生成過程が物理法則に従うか」を重視する方向に移行しており、将来的にはこの分野の「ImageNet」となる統一基準の確立が期待されています。
第8章 課題と今後の展望(Challenges & Future Directions)
本章では、物理認知動画生成の主要課題と、今後の研究方向が整理されています。 現状では、個別現象に特化したモデルが多く、汎用性・再現性・解釈性の面で課題が残ります。
🔹 汎用物理モデルの欠如: 現象ごとに異なるモデルが必要で、統一的枠組みが存在しません。
🔹 Sim2Realギャップ: シミュレーターでの挙動が、現実環境と乖離することがあります。
🔹 モダリティの制限: 視覚中心の学習に偏り、音・触覚などの感覚情報を十分に扱えていません。
🔹 高コストな物理計算: 高精度なシミュレーションや微分方程式解法には膨大な計算リソースを要します。
🔹 データ不足とアノテーションの困難さ: 実世界データの収集が難しく、教師データの偏りも課題です。
🔹 評価基準の不統一: 各研究で「物理的一貫性」の定義が異なり、比較が困難です。
🔹 解釈可能性の欠如: モデルがどのように物理推論を行っているのか説明が難しいです。
これらの課題を背景に、今後の方向性として「統一物理モデル」「神経物理ハイブリッドシミュレーション(Neuro-Physical Hybrid Simulation)」「説明可能な物理推論」が提案されています。 また、実世界でのデータ取得が難しい状況を補うため、自己教師あり学習・模倣学習・世界モデル統合などの研究も進展しています。
最終的な目標は、AIが人間のように「世界を理解し、想像し、予測する」能力を持つことであり、ロボティクスや科学発見支援など、知能の新たな応用領域への展開が期待されています。
第9章 結論(Conclusion)
本論文は、AIによる動画生成を「視覚的一貫性」「物理的一貫性」「認知的一貫性」という三層の枠組みで体系化しました。 真に物理的な認知を備えたAIとは、単にリアルな映像を描くだけでなく、背後の物理法則を理解し、未来の変化を予測できる存在です。
物理に基づく生成AIは、仮想世界で「頭の中の実験」を行う新しい知能体として発展しつつあり、人類に「世界シミュレーション知能(Simulation Intelligence)」という新たな知的パラダイムをもたらす可能性を秘めています。
引用: A Survey on Physical Understanding in AI-based Video Generation (arXiv:2503.21765v1)
リソース: Awesome-Physics-Cognition-based-Video-Generation (GitHub)


 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。