2024年12月20日
こんにちは!AI/BI部のCです。
今回は、Go標準ライブラリの sort.Search のソースコード実装について皆さんと議論したいと思います。最近この関数を使用する際に中身のソースコードを確認したところ、なんと二分探索アルゴリズムが実装されていることに気付きました。汎用的な検索インターフェースに、特定の場面で使用される二分探索が採用されていることに驚き、とても興味深く感じたので、これを機に詳しく探究してみることにしました。
二分探索とは、ソートされたデータ集合に対して効率的に特定の値を検索するアルゴリズムのことです。このアルゴリズムでは、探索範囲を毎回半分に分割し、目的の値が存在する範囲を絞り込むことで、高速な検索を実現します。探索範囲が縮小するたびに比較回数が減るため、大量のデータを扱う場合でも効率的に動作します。
時間計算量は O(log n) です。
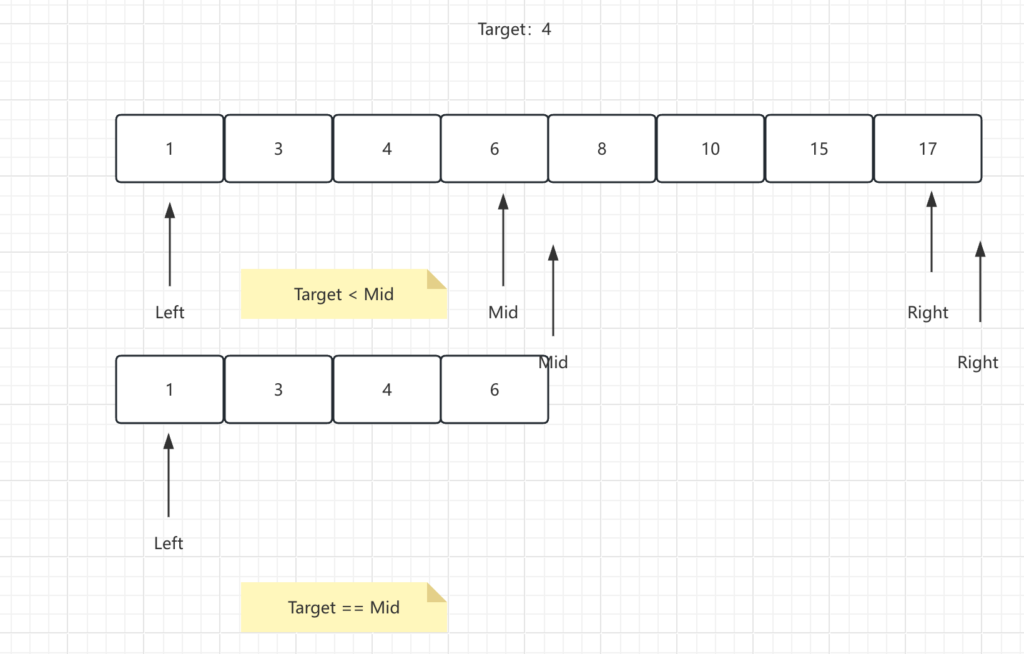
上の図のように、配列の中央の値が目標値と一致するかを毎回確認します。一致しない場合は、左側の範囲または右側の範囲を確認し、新しい範囲内で再び中央の値を確認します。この手順を繰り返すことで、最終的には3回の探索だけで結果を得ることができました。
func binarySearch(nums []int, target int) int {
res := -1
left := 0
right := len(nums) - 1
for left <= right {
mid := (left + right) / 2
if nums[mid] == target {
return mid
} else if nums[mid] > target {
right = mid - 1
} else {
left = mid + 1
}
}
return res
}とてもシンプルで、左右のポインタの境界に注意するだけで大丈夫です。
func SearchInts(a []int, x int) int {
return Search(len(a), func(i int) bool { return a[i] >= x })
}
func Search(n int, f func(int) bool) int {
// Define f(-1) == false and f(n) == true.
// Invariant: f(i-1) == false, f(j) == true.
i, j := 0, n
for i < j {
h := int(uint(i+j) >> 1) // avoid overflow when computing h
// i ≤ h < j
if !f(h) {
i = h + 1 // preserves f(i-1) == false
} else {
j = h // preserves f(j) == true
}
}
// i == j, f(i-1) == false, and f(j) (= f(i)) == true => answer is i.
return i
}ここで2点説明が必要です。
int(uint(i+j) >> 1) の右シフト演算についてです。これは2進数に変換して1ビット右にシフトすることで、実質的に2で割る効果を持ちます。ここでは、桁あふれを防ぐために使用されています。return nums[i] >= 1 を渡します。この方法の利点は2つあります。
func main() {
nums := []int64{1, 2, 3, 4, 5, 6, 7}
fmt.Println(sort.Search(len(nums), func(i int) bool {
return nums[i] == 1
}))
}
結果は7!func main() {
nums := []int64{1, 2, 3, 4, 5, 6, 7}
fmt.Println(sort.Search(len(nums), func(i int) bool {
return nums[i] >= 1
}))
}
結果は0!func main() {
nums := []int64{1, 3, 4, 5, 6, 7}
fmt.Println(sort.Search(len(nums), func(i int) bool {
return nums[i] >= 2
}))
}
結果は1!ここでは結果の違いが確認できます。return >= 1 の式を使用することで、正しく目標のインデックスを見つけることができます。また、目標値が見つからない場合でも、適切な挿入位置が見つかります。
ソースコードの二分探索の実装では、式を引数として渡すことで、さまざまな検索要件に適応できるようになっています。
sort.Search のソースコードを確認すると、内部的には二分探索で実装されていることが分かります。つまり、対象となるスライスがソートされていない場合、この関数を使用することはできません。そのため、無秩序なスライスに対しては、まず sort.Sort() メソッドを使用してソートを行い、その後で sort.Search を使用して検索する必要があります。
これが今年最後のブログ記事となります。今月は Python の asyncio や requests を使用する際に遭遇した問題とそのソースコードの解説、そして Go 言語の sort.Search のソースコード解析をシェアしました。来年はまた別の内容を共有していきたいと思います。それでは、良いお年を!

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。