2024年12月17日
こんにちは、AI/BI部のLです。
テーマはずっと前から決まったのですが、ちょうど最近(2024年12月)、Ilya Sutskeverとか、Fei Fei Liとかの有名人たちは大型AIモデルにおけるテキストデータのボトルネック問題を言及しました(Ilya Sutskever、Fei Fei Li)。今回はその原因と展望について語りたいと思います。
テキストデータと言えば、もちろん、画像をテキスト記号として保存すればそれもテキストデータになるし、時系列モデルに入力できる原因ともなります。
でうが、ここの「テキスト」は、主に「自然言語」を指しています。それは何かというと、日常生活の中に使われている言葉だけじゃなくて、言葉や意味に合意があるものの変わりつつあるコミュニケーションツールです。日常的に用いる言語との違いに関して、次の例で説明します。
あるチャットルームに、皆さんが仲良く話し合っていました。ですが、ある日、誰かが危ない話題を持ち込んだため、チャットルームは段々と悪口と嫌がらせしかなくなりました。そこに、管理者が一時的に、選択肢にある定型文だけ使えるように設定しました。定型文を使えば例え悪口を言いたくても二進数文字みたいなものになってしまうので、当然嫌がらせをする人がいなくなったが、チャットルームに他の人もいなくなりました。
ここに、定型文が設定された前にみんなが使っている言葉は、自然言語でした。上記の例では、「定型文」という極端な例を挙げたが、実は「一定の構文ルールの下に辞書から言葉を組み合わせる」のも自然言語ではない場合も多いです。ですから、人が口にする言葉が必ずしも自然言語とは限らず、閉集合がない自由さを持つコミュニケーションツールこそが自然言語なのです。
個人的に、「知恵の結晶」と言われてきたが、言語の本体は「結晶」という結果だけじゃなくて、「結晶化」という過程も含まれるかと思います。なぜなら、言葉は、現実世界の何かを他の人に伝えたいために作られたからです。同じ理由で、標準語が何回更新されても、新しい方言は出てきます。ですから、いくら「文法」に工夫を凝らしても、形式言語はLLMの能力に及ぶのは難しいでしょう。
「文脈」、文字や音声によく使われる言葉ですが、実は視覚情報にもあります。機械学習の視点なら話しやすいですね。ローカル特徴を見るだけで、全体的にそのものは何かがわからないです。ゆえに、文字や音声みたいに、空間の前後にある特徴も参考すれば、そのローカル特徴の「意味」もわかるようになれます。(前回の記事にAttentionで「xくんが強化される」もこういうことです)
より普通な説明であれば、映画の中にセリフが出ていない画面の中に、セリフがなくてもカメラの観測の変換によって、見えるものが変わって、最後にできた「イメージ」が「視覚的文脈」となります。この二つの解釈もちょうど、前回の記事に言った「情報を統合する機構」と人間における「注意」でした。
ゆえに、「文脈」の機能から見ても、視覚情報は自然言語情報に劣れていないことは一つ目の結論です。
現実世界でも、人間のイメージによる人間社会でも、ピタゴラスイッチみたいな連鎖的な作用は溢れています。例えば、時に些細な原因でも遅延が溜まって行って、道路や鉄道が大渋滞になります。また、同じ都市にあっても、具体的な環境によって、寒くなったり、暖かくなったりはします。
ですが、それらの現象と周りの要素との結びつきが、必ずしも言語化されるわけではありません。より一般的なのは、みんながそれを暗黙的に理解することです。そう見ると、実はLLM(Large Language Model)が使えないデータは現実世界に結構あるはずです。
ゆえに、インターネットにあるテキスト情報を全部利用しまくっただけで、「大型モデルはデータボトルネックにぶち当たった」ということは本当に言えるのでしょうか?
あと、物理シミュレーションそのものさえも大々的にディープラーニングを導入している中、現実世界のデータを学習するよりも低コストなデータ合成方法をどうやって見つけ出せるのでしょうか?
と、僕と話し合ったところ、gptくんが親父Ilyaの発言に対してこういう疑問を投げかけました。(😆)
これを二つ目の結論とします。
これから最後のMythを解きほぐしてみます。その問題は、「頑張れば、文字だけで全ての視覚情報を表現することはできますか?」
まずは以下のプロンプト文を見ましょう。
「未来都市の夜明けの情景:空は深い紫から黄金色へと移り変わるグラデーションで彩られ、巨大なガラスの建物群が太陽の光を反射している。都市の間を飛行車が行き交い、遠くには雲の上までそびえる非対称な形の塔があり、その頂上には浮かぶ光の輪が輝いている。街路にはネオン光を放つ衣服をまとった人々が歩き、ロボットと人間が共に活動している。穏やかでありながら活力に満ちた雰囲気が広がっている。」
そして、DALL-E 3とSORAの出力は以下となります。
![]()
気づいた方もいると思いますが、両方の出力が全く違う、というのは、非可逆圧縮となっています。この非可逆圧縮である文字は、果たして、すべての視覚情報を表現することができますか?
ほぼできないと思います。できるとしても、「画像をテキスト記号として保存すればテキストデータ」みたいなことになります。
もちろん、上記の比較は十分に厳密ではなさそうなので、もう一つの例を挙げて頂きましす。
「僕は三十七歳で、そのときボーイング747のシートに座っていた。 その巨大な飛行機はぶ厚い雨雲をくぐり抜けて降下し、ハンブルク空港に着陸しようとしているところだった。 十一月の冷ややかな雨が大地を暗く染め、雨合羽を着た整備工たちや、のっぺりとした空港ビルの上に立った旗や、BMWの広告板やそんな何もかもをフランドル派の陰うつな絵の背景のように見せていた。 やれやれ、またドイツか、と僕は思った。」
この段落の中にある「十一月の冷ややかな雨が大地を暗く染め」と「フランドル派の陰うつな絵の背景」を作者が表したい風景にそのまま変換するのが不可能です。なぜなら、人が言葉を口にする時にも、人が言葉を理解する時にも、必ず主観的なイメージが伴ってしまうからです。その主観的なイメージによって、同じ言葉が指し示すものには複数の可能性があります。
ですから、残念ですが、変換には正確な一対一対応が必要なので、頑張っても、文字だけで全ての視覚情報を表現することは、できません。
1. 視覚情報にも文脈があります。
2. 人々は必ずしも感じたものを文字化するわけではありません。
3. 文字だけで全ての視覚情報を表現することはできません。
上記の三つの結論から考えると、テキストデータだけでなく、現実世界の視覚データなども重要である理由がご理解いただけたのではないでしょうか。
画像データの進歩についてあれこれ語りましたが、決して文字そのものを軽んじるつもりはありません。ただ、脳を神秘化するのと同じように、文字に対する神秘化(Myth)を少し解きほぐしてみたいだけなのです。
実は逆に、文字を利用しなければ、現実世界の情報を活用することも難しくなります。なぜなら、Embodied AI(つまりロボット!)を使って、視覚や音声情報の特徴抽出能力をテストしようとしても、現状、材料かエネルギーの制限によって、ロボットの体はそれほど複雑なタスクを実行できないからです。
これからは、どのように文字を利用して現実世界の情報を活用するかを予測してみます。
何年前に、またOpenAIが、CLIPという手法を提出しました(https://openai.com/index/clip/)。タスクは分類だけなんですが、類似度の計算によって、文字と画像の特徴のalignmentができることを示唆しました。ですが、それだけで「視覚情報から学んだ概念の間の関係情報はどのようにテキスト生成に使えるか」は解決していません。
LLMはテキストでトレーニングすることで、「この文字列に対してはどんな文字列を出力されるのが期待されているか」について学ぶことができます。そこに、「視覚情報から学んだ概念の間の関係情報」は即ち、そういう情報の視覚バージョンです。今時のSORAなどの大型動画生成モデルはすでにそれを実現しています。
問題は、どのように視覚と文字データから学んだ概念関係情報をマージすることです。
個人的には、「Text2Visual」、「Visual2Text」、「Visual2Visual」、「Text2Text」四つのタスクで同時にトレーニングできるモデルは「Text2Text」の部分に視覚経験を利用できる可能性があると思います。
もちろん、現実世界の中に、そもそもテキストという記号みたいなものはあくまでちょっと特別な視覚情報だけなんですが(それで同じ時系列の中にあり得る)、コンピュータに対しては、多分テキストと視覚情報の空間を分けたほうが楽かもしれないですね。
ここに、よく異なる空間の情報を利用する手法「Cross Attention」を紹介します。(前回の記事にもある下記の画像がCross Attentionです)
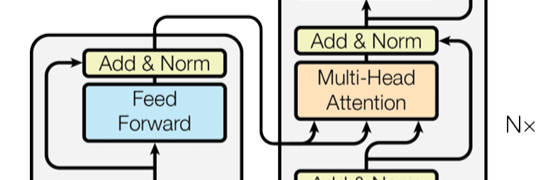
例えば、モデルの入力情報は視覚情報であれば、右に入力されるKとVが視覚特徴です。QだけはDecoderの入力から変換されてきたので、モデルが求めているテキスト情報はそのQが代表しました。これで、「求めたいものに関する情報」と「参照物に関する情報」をAttentionのQとKで融合し、また「参照物に関する情報」の要点を取り出すのが、この「Cross Attention」でした。
そこに、Text(K1V1)→Visual(Q1)、Visual(K2V2)→Visual(Q2)、Visual(K3V3)→Text(Q3)というルーツに通せば、K1、K2、K3、Q3に類似性が築かれます。結果的に、Text(K1V1)→Text(Q3)というタスクは暗黙的にK2とQ2の関係情報を利用できる可能性があります。
社員Lです。三週間のブログ更新はようやく終わりました。
少し寂しい気持ちもあるけれど、みんながブログを書くのも大変ですね。なので、すべてのブログを完成できる自体は幸いだと思います。
他の記事と比べれば、僕の三本の記事は実装知識に欠けていますが、これらの記事を通して生成AIと深層学習の全体像を多少もたらせるのならすごく嬉しく思います。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。