2024年12月16日
おはようございます!AI/BI部のA.Kです。
前回の投稿から少し時間が空きましたが、またこうして新しい記事をお届けできることを嬉しく思います。
前回の投稿ではPLS回帰と構造化データの整合性の関連性についてお話ししましたが、今回では具体的なやり方について深掘りしていきます。
なるべく役立つトピックや情報を盛り込んでいきますので、ぜひ最後までお付き合いください。それでは、さっそく始めましょう!
PLS回帰を利用して、構造化データの整合性をチェックする際に、まずPLS回帰を利用して、データに対して、回帰モデルを作成(適合)しないといけないとのことです。
以下は実際CSVデータからPLS回帰モデルを作成するまでのPythonソースコードになります。
# 必要な関連ライブラリをインポートする
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cross_decomposition import PLSRegression
from sklearn.metrics import r2_score, mean_absolute_error
from sklearn.model_selection import cross_val_score
# データ準備および正規化の変換処理
# ----------------------------------------------------
# チェックしたい構造化データ読み込みと説明変数Xと目的変数yの生成
df_ref = pd.read_csv('test_data.csv')
y = df_ref['目標値'].to_numpy()
X = df_ref.loc[:,'説明変数A':'説明変数E'].to_numpy()
# 説明変数Xに対して、z-score正規化によるデータ標準化
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0)
X_zscore_normalized = (X - X_mean) / X_std
# 目標変数に対して、オリジナル値をそのまま利用する
y_zscore_normalized = y
# クロスバリデーションの検証
#--------------------------------------------------
# コンポーネント数の候補
n_components_list = [1, 2, 3, 4, 5]
# 平均二乗誤差(MSE)を格納するリスト
mse_list = []
for n in n_components_list:
pls = PLSRegression(n_components=n)
mse = -np.mean(cross_val_score(pls, X_zscore_normalized, y_zscore_normalized, cv=5, scoring='neg_mean_squared_error'))
mse_list.append(mse)
print(f'n_components = {n}, MSE = {mse:.4f}')
# 最適なコンポーネント数の選択
optimal_n = n_components_list[np.argmin(mse_list)]
print(f'最適なコンポーネント数: {optimal_n}')
# PLS回帰モデルの構築と学習
#--------------------------------------------------
pls = PLSRegression(n_components=optimal_n)
pls.fit(X_zscore_normalized, y_zscore_normalized)
y_pred = pls.predict(X_zscore_normalized).ravel()
r2 = r2_score(y_zscore_normalized, y_pred)
mae = mean_absolute_error(y_zscore_normalized, y_pred)
print(f"決定係数 R^2: {r2:.4f}")
print(f"平均絶対誤差 MAE: {mae:.4f}")
🎉おめでとうございます!チェックしたい構造化データに対して、PLS回帰モデルの作成が完成しました🎉
PLS回帰の適合結果から異常データチェックする際に、まずスチューデント化残差プロットを求めることが必要です。
どういうことですと、簡単に言えば、回帰診断と同じく、回帰適合した上の数学モデルの予測値を利用して、影響度の大きいデータ(予測値と実際値の偏差が大きい)はないか等のチェックをする工程です。
スチューデント化残差 (Studentized residual) は、従属変数の予測値の信頼性についてデータセットの中央を高く考慮する標準化残差です。 極端なデータポイント (独立変数の最小値と最大値を持つデータポイント) の残差の値に重みを付けることによって、標準化残差に比べて外れ値の検出の感度が高くなります。
場合により、外部スチューデント化残差 (externally Studentized residual) とも使われる、推定量の標準誤差を使用し、この残差に関係するデータポイントを削除した後に計算を行うスチューデント化残差です。分散の計算からこのデータポイントを削除することによって、外れ値に対する影響がより大きくなります。
今回はより分かりやすく異常データポイントを発見するため、外部スチューデント化残差の利用をご紹介致します。
以下は上記作成したPLS回帰モデルから外部スチューデント化残差プロットを出力するまでのPythonソースコードになります。
# 残差(予測値と実際値の偏差)の計算
residuals = y_zscore_normalized - y_pred
# 残差の平均二乗誤差(MSE)の計算
MSE = np.mean(residuals ** 2)
# スコア行列の取得
T = pls.x_scores_
# レバレッジの計算
leverages = np.sum(T ** 2, axis=1) / np.sum(T ** 2)
# 外部スチューデント化残差の計算
#--------------------------------------------------
n = n_samples
p = pls.n_components # 使用したコンポーネント数
RSS = np.sum(residuals ** 2)
externally_studentized_residuals = np.zeros(n)
for i in range(n):
# i番目の観測値を除いた残差平方和と自由度
RSS_i = RSS - residuals[i] ** 2
#自由度参考資料
# https://ja.wikipedia.org/wiki/%E3%82%B9%E3%83%81%E3%83%A5%E3%83%BC%E3%83%87%E3%83%B3%E3%83%88%E5%8C%96%E6%AE%8B%E5%B7%AE
# https://www.business-research-lab.com/211105-2/
df_i = n - p - 2 # i番目を除いたため、自由度が1減る
s_i = np.sqrt(RSS_i / df_i)
externally_studentized_residuals[i] = residuals[i] / (s_i * np.sqrt(1 - leverages[i]))
# プロットの作成
plt.figure(figsize=(10, 6))
plt.scatter(leverages, externally_studentized_residuals)
plt.xlabel('Leverage')
plt.ylabel('Externally Studentized Residual')
plt.title('Externally Studentized Residuals vs Leverage')
plt.grid(True)
plt.show()
🎉おめでとうございます!チェックしたい構造化データに対して、スチューデント化残差プロットの出力が完成しました🎉
以下の例図で示された通り、プロット上で±2の範囲(オレンジ色の線)を超える点(仲間外れのデータ)は、異常値または外れ値の可能性が高いです。これらのデータポイントを個別に確認することで、構造化データの整合性チェックが可能です。
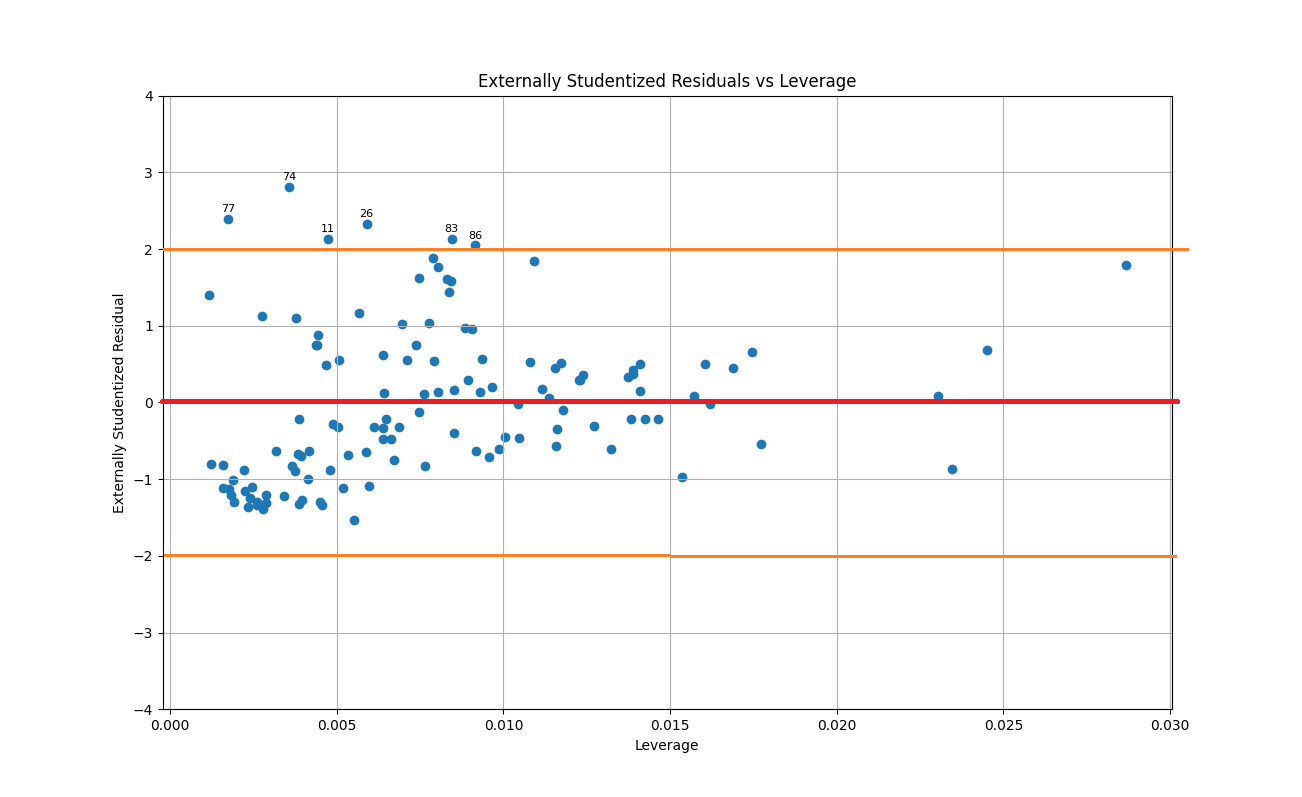
スチューデント化残差プロットから示す異常値に関して、以下の整合性問題に関わる確認ポイントが考えられます:
1,異常なデータ入力:プロット上で明らかに目立つ点を調査し、エントリミスがないかを確認すること。
2,スキーマ違反の検出:データの一部項目の値が期待される値の範囲外になっているかを確認すること。
3,データ分布の偏り:残差が均一に分布していない場合、全体データと比べて構造的な偏りが存在するデータの可能性を確認すること。
上記3の場合は実際運用上、そういうような偏りデータの発生頻度を確認する必要があります。運用として無視してはいけない場合は過去例がすくないため、AIモデルよりは例外処理を追加したほうが良いと考えられます。
今回は簡単にPLS回帰を利用してデータの整合性チェックを3ステップで紹介させていただきました。
繰り返しますが、シンプルにすると、「PLS回帰モデルの作成」ー>「スチューデント化残差プロットの出力」ー>「プロットから異常データの確認」の3段階になります。
いかがでしょうか?
次回はPLS回帰により、異常データを削除してからAIモデルを作成する際に、精度の改善に役立つかどうかを紹介していきたいです!
この2週間、気温が一段に下がってるので、みんなはくれぐれも体調管理しながら、元気にお過ごしください!
それでは、あた。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。