2024年12月27日
こんにちは。新入社員のYSです。
今回は12月末に行われた勉強会の様子をお伝えしようと思います。
最初の発表は同じ部署の先輩のWさんでした。今回はお仕事の都合上、会社には不在でしたが録画での発表となりました。
Wさんは趣味でギターやベースなどを嗜んでおり普段から様々な曲を弾いていらっしゃるそうなのですが、引きたい曲の楽譜(TAB譜)がなかったり、耳コピして楽譜を作成するには複雑すぎる曲などが多く存在するそうです。
そこから動画や音声のデータで楽譜を生成するものがあれば便利とのことで今回のシステムを作成されたそうです。
生成する楽譜はピッチやビートの検出やある程度の歪みやノイズは分離して生成されるものを作成されていました。
作成された楽譜は印刷や共有が可能な形式で出力可能ですがまだ解析のアルゴリズムの改良の余地やエフェクトが強くかかったギター特有の奏法への対応など様々な改善点があるようです。

このシステムが改善されていき自動で楽譜が作成されるものが世に出回れば全世界のギタリストは大歓喜間違いなしだと思います。
二人目の方はOさんです。OさんはAmazon S3(Amazon Simple Storage Service) というAmazonが提供するストレージサービスについて勉強されておりました。
Amazon S3は高い耐久性とスケーラビリティを持つAWSのオブジェクトストレージサービスで、データの保存やバックアップ、静的コンテンツ配信など幅広い用途で使われているもののようです。

Amazon S3ではバケットと呼ばれるデータを格納するためのコンテナとオブジェクトと呼ばれるバケット内に保存されるデータの単位、バケット内のオブジェクトを識別するキーでデータ構造が構成されているようです。Salesforceとのデータ構造と似ていますが少し異なるようですね。
そしてAmazon S3をSalesforceで使用するための方法についても勉強されていました。SalesforceでAmazon S3が利用できれば大容量のファイルやデータをS3に保存できるため、コストを抑えつつ大量のデータを安全に管理できるので私も詳しく勉強したいなと感じました。
そして最後に私YSの発表です。
私は入社前までプログラミングの専門学校でAIについて勉強していたこともあり今回はAIを使用した音声合成について勉強しました。
最近巷ではAIの音声合成を使用した歌の動画や解説動画などが多々見受けられました。そんな動画たちの音声はどのように作られているのか気になったので自分の声で作ってみることにしました。
今回はElevenLabsというツールを使用し自分の音声モデルを作成しました。こちらのツールは他の音声合成のツールに比べ学習速度が速く、日本語に対応しているのと自分の音声合成を作成できる点と、何よりとても安価で利用できました。(500円ほど)
ElevenLabsは主にディープラーニングとNLPと呼ばれる自然言語処理を利用されており、特にトランスフォーマーアーキテクチャと呼ばれるモデルが基礎となっております。そのモデルに含まれる大量のデータからパターンを学習し入力テキストに応じ文脈に合うように自然な発音が発せられるようになっております。
用意したサンプルデータは3分程度のものなのですが学習時間がとても速く1分とかからずに学習を終え自分の音声データを作成することができました。
今回はブログのため音声を乗せることはできませんが、自分の声がテキストを違和感なく読み上げているのを聞くと感動を覚える半面、こんなに簡単に音声合成できることに対し不安を感じました。以下は作成した音声合成データをHTML上で動作させるためのPythonコードです。
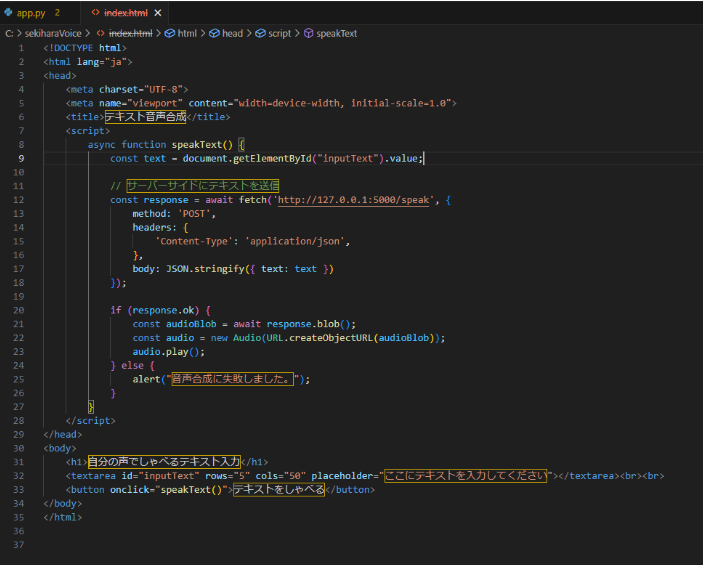
AIによる音声合成は以前までは作成するのにも大量データが必要であったりそこから自然な発音を出すことも難しいとされていましたが、これほど手軽にできる技術の発展スピードに驚くと同時に運用するにあたって音声合成のされるデータ元の人間の意志の尊重や著作権などを意識したり、今後増えてくるであろうディープフェイクなどによるインターネット上の誤った情報などを正しく判断する必要があるなと感じました。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。