2024年12月23日
こんにちは!AI/BI部のA.Kです。
2024年も残りわずかとなり、今年自分の最終投稿をお届けする時期となりました。12月、AI/BI部のみんなと一緒に、IT技術に関するさまざまなトピックを共有できたことを大変嬉しく思います。
年末のこのタイミングで、前回投稿内容の振り返りをしつつ、今後の技術動向や知見を皆さんと一緒に深めていける記事をお届けできればと思っています。今年最後の投稿もぜひ楽しんでいただけると幸いです。それでは、始めていきましょう!
前回はPLS回帰を利用して、構造化データの整合性をチェックする実践方法を簡単に紹介させていただきました。
その整合性チェックが終わって、AI学習の段階に踏み出すとのことですが、その中でに、近年注目を集めているのが「LightGBM」というライブラリです。この投稿では、LightGBMの概要、特長、そしてどのように実際のプロジェクトで活用できるのかを詳しく解説していきます。
LightGBM(Light Gradient Boosting Machine)は、Microsoftが開発したオープンソースの勾配ブースティングアルゴリズムです。特に、大規模な構造化データの処理や、高速なモデル構築を得意としています。XGBoostなどの他のブースティングアルゴリズムと同様、回帰や分類タスクに幅広く利用されています。
LightGBMが他のアルゴリズムと一線を画す理由を以下に挙げます:
① 高速性と効率性
LightGBMは、ヒストグラムベースの分割アルゴリズムを採用しており、計算速度が非常に高速です。大規模データを扱う際に、その効率性が特に発揮されます。
よく、AI学習と稼働でGPUが必要と聞かれると思いますが、LightGBMではGPUに依存せず、一般的なノートPCのCPUだけでも高速化実行することが可能です。
② メモリ使用量の削減
LightGBMは、葉ごとの成長戦略(Leaf-wise Tree Growth)を採用しており、従来の深さごとの成長戦略(Level-wise Growth)に比べて、メモリ使用量を抑えることができます。
③ カテゴリカルデータのサポート
構造化データには、カテゴリカルデータ(例:性別や地域)が多く含まれますが、LightGBMはデフォルト関数の利用でこれを直接処理可能です。事前にエンコーディングを行う必要がないため、前処理の手間を大幅に削減できます。
④ パラメータの柔軟性
LightGBMは、多数のハイパーパラメータを提供しており、タスクに応じた細かいチューニングが可能です。これにより、モデルの性能を最大化できます。
※ 精度向上するため、チューニングを実施すればするほど時間がかかりますが、公式外のライブラリを活用して、自動的に数のハイパーパラメータの中、最適なパターンを探索することができるので、後程紹介いたします。
以下は、Pythonを用いてLightGBMを実装する際の基本的なコード例です:
# 必要な関連ライブラリをインポートする
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cross_decomposition import PLSRegression
from sklearn.metrics import r2_score, mean_absolute_error
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
import lightgbm as lgb
# データ準備および正規化の変換処理
# ----------------------------------------------------
# チェックしたい構造化データ読み込みと説明変数Xと目的変数yの生成
df_ref = pd.read_csv('test_data.csv')
y = df_ref['目標値'].to_numpy()
X = df_ref.loc[:,'説明変数A':'説明変数E'].to_numpy()
# 説明変数Xに対して、z-score正規化によるデータ標準化
X_mean = np.mean(X, axis=0)
X_std = np.std(X, axis=0)
X_zscore_normalized = (X - X_mean) / X_std
# 目標変数に対して、オリジナル値をそのまま利用する
y_zscore_normalized = y
# LightGBMでの構造化データの学習
#--------------------------------------------------
# lightgbm regressor
SEED = 42
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
shuffle=True,
random_state=SEED
)
# データセットを登録
lgb_train = lgb.Dataset(X_train, y_train)
lgb_test = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {
'task': 'train', # タスクを訓練に設定
'boosting_type': 'gbdt', # GBDTを指定
'objective': 'regression_l1', # 回帰を指定
'metric': 'mape', # 回帰の評価関数
'learning_rate': 0.1, # 学習率
'feature_pre_filter': False, # optional
'lambda_l1': 0.0, # optional
'lambda_l2': 0.0, # optional
'num_leaves': 31, # optional
'feature_fraction': 1.0, # optional
'bagging_fraction': 1.0, # optional
'bagging_freq': 0, # optional
'min_child_samples': 5, # optional
'num_iterations': 100 # optional
}
lgb_results = {} # 学習の履歴を入れる物
model = lgb.train(
params=params, # ハイパーパラメータをセット
train_set=lgb_train, # 訓練データを訓練用にセット
valid_sets=[lgb_train, lgb_test], # 訓練データとテストデータをセット
valid_names=['Train', 'Test'], # データセットの名前をそれぞれ設定
num_boost_round=100, # 計算回数
callbacks=[lgb.early_stopping(stopping_rounds=20, verbose=True), # early_stopping用コールバック関数
lgb.record_evaluation(lgb_results), # 学習の履歴を保存
lgb.log_evaluation(period=-1)], # コマンドライン出力用コールバック関数
)
#最適化したパラメータを表示する。
best_params = model.params
print(best_params)
print(model.best_iteration)
# 学習できたAIモデルの出力
model.save_model('model_1218_test.txt')
# 学習履歴の表示
loss_train = lgb_results['Train']['mape']
loss_test = lgb_results['Test']['mape']
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_xlabel('Iteration')
ax1.set_ylabel('logloss')
ax1.plot(loss_train, label='train loss')
ax1.plot(loss_test, label='test loss')
plt.legend()
plt.show()
🎉おめでとうございます!構造化データに対して、LightGBMで回帰モデルの作成が完成しました🎉
ちなみに、学習時間の推移での精度変化は以下の感じになります。
縦軸は誤差、横軸は学習の時間推移です。
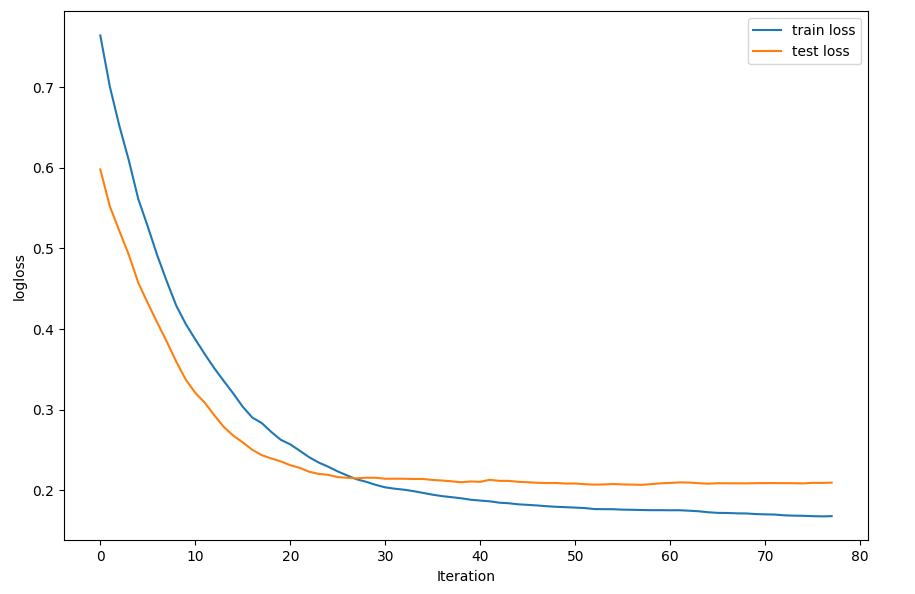
前述の通り、精度を保つため、学習する際に、ハイパーパラメータのチューニングを実施すると、かなり時間かかると予想されますが、optuna社が無料提供しているライブラリを利用すると、手作業から解放して、自動化になります。
ライブラリの利用方法は非常にシンプルでさきほどのコードの中、最初のimportのところ、1行を増やすほどで、他は変更してなくても、学習する際に、ハイパーパラメータの探索が自動的にやってくれます。最終的に結果として一番良い学習結果になるパラメータが表示されます。
以下は、Pythonを用いてLightGBMを実装する際の基本的なコード例です:
# 必要な関連ライブラリをインポートする
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cross_decomposition import PLSRegression
from sklearn.metrics import r2_score, mean_absolute_error
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# ↓以下の1行を増やすだけでOKです。
import optuna.integration.lightgbm as lgb
以下は、自動チューニング後の結果となります。一番良いパラメーターが出力されていることが確認できました。

今回はLightGBMとその使い方を簡単に紹介させていただきました。
僕の今年12月のAdvent Calendarの最終投稿となっているんですが、とても有意義な技術共有が出来ており、来年また機会があれば、再度社内活動として開催できれば良いと思います。
年末の挨拶を兼ねて、今回の投稿内容は以上とさせていただきます。
みんな、よいお年をお迎えください。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。