2024年12月22日

こんにちは。この記事はSOHOBB AI/BI Advent Calender 2024の22日目の記事となります。
私の担当記事では、「JPEGエンコーダーをつくろう」と題して画像圧縮符号化における基礎的な技術についてPython実装を交えながら紹介しています。
前回は、JPEGエンコーダーにおけるDCTと量子化について紹介しました。DCTでは画像のYCbCr信号をコサイン基底を用いた周波数領域での表現に変換し、空間的な冗長性を取り除きました。また、人間の視覚が高周波の変化に鈍感である特性を利用し、周波数に応じて量子化幅を変えていました。
今回は、量子化されたDCT係数を符号化し最終的なJPEGファイルに出力する内容について紹介したいと思います。
JPEGエンコーダーの役割は、画像をより小さくコンパクトに圧縮することでした。コンピューターにおいては、画像をピクセル単位で表現しますが、実際にファイルとして蓄積する際には元のピクセルを一意に復号可能な符号を割り当てられた符号列で蓄積します。
前回まで取り扱ってきた情報量の削減とは異なり、符号化の前後で得られる情報量に差異はありません。
ここで、情報量とはシャノンの情報理論における情報量を指します。情報量は、その具体的な意味や内容とは無関係に、事象の起こりにくさによって決定されます。たとえば、事象Eの起こる確率をP(E)とすると、Eの情報量は以下の式で表されます。
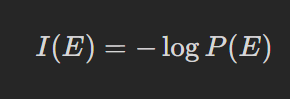
このときの情報量を事象Eの自己情報量と呼び、各事象の自己情報量の期待値を平均情報量(エントロピー)と呼びます。
平均情報量は、事象ごとの確率に偏りが少ないほど(次にどの事象が起こるか不確実性が高いほど)大きくなります。また、符号化においては、平均情報量はある情報源を符号化した際のシンボルが平均で持つ情報量を表しているといえ、いかなる符号化方式であっても情報源の平均情報量を下回ることはないといえます。
そうです、画像を圧縮するうえでDFTやDSTと比較してエネルギー圧縮で優位なDCTが用いられる場合が多いのは、係数の平均情報量を小さくするための工夫でもあります。
Huffman符号は、シャノンの平均情報量にもとづき効率的な符号割り当てを行うエントロピー符号化の一種です。出現頻度の高いデータに対して短い符号を割り当て、出現頻度の低い符号に長い符号を割り当てることで全体の符号列長が短くなるよう工夫されています。
JPEGでは、DC/AC成分それぞれを中間表現に変換した後Huffman符号によって符号を割り当てています。具体的には、DC成分についてはDPCM、AC成分についてはRLEを適用しています。
DC成分については、そのブロックの平均輝度を表していました。各ブロックのDC成分の大きさは画像によってまちまち(暗い画像から明るい画像まで)ですが、画像の空間的な相関を考えると、隣接するブロック間でのDC成分の差は小さくなる場合が多いです。
そこで、JPEGではDC成分をラスタスキャン順に並べて差分をとるDifferential Pulse Code modulation(DPCM)を適用して符号化対象の範囲を小さくしています。
AC成分では、DCTによって低周波数成分にエネルギーが集中する性質がありました。また、DCT係数の量子化においても高周波数成分ほど粗く量子化していました。このため、高周波数成分ほど量子化後の係数がゼロである確率が高くなる傾向があります。
そこで、JPEGではAC成分をZig-Zagスキャン(低周波数成分から高周波数成分)順に並び変え、Run-Length Encoding(RLE)を適用しています。低周波数成分から高周波数成分に並べることで、AC成分列には高い確率でゼロが連続するゼロランが出現するため効率的に符号化することができるようになります。
さて、DC/AC成分の符号化器を実装しましょう。
実際のJPEGでは、セグメントと呼ばれるいくつかの領域に分けて情報を記録しています。各セグメントの識別子やデコードの都合から予約されたコードや制約が設けられていますが、これまでのペースで言及すると非常に長くなりそうだったので割愛します。
ZIGZAG_ORDER = np.array([
0, 1, 8, 16, 9, 2, 3, 10,
17, 24, 32, 25, 18, 11, 4, 5,
12, 19, 26, 33, 40, 48, 41, 34,
27, 20, 13, 6, 7, 14, 21, 28,
35, 42, 49, 56, 57, 50, 43, 36,
29, 22, 15, 23, 30, 37, 44, 51,
58, 59, 52, 45, 38, 31, 39, 46,
53, 60, 61, 54, 47, 55, 62, 63])
def dpcm(coeffs: npt.NDArray):
r, c = coeffs.shape[:2]
# DC成分を抽出
dcs = coeffs[:, :, 0, 0].reshape(-1)
# DPCM
dc_diff = np.diff(dcs, prepend=0)
# size と additional bitsのペアに変換
symbols = []
for v in dc_diff:
s = __cvt_to_size_and_bits(int(v))
symbols.append(s)
symbols = [symbols[i : i + c] for i in range(0, len(symbols), c)]
return symbols
def rle(coeffs: npt.NDArray):
r, c = coeffs.shape[:2]
symbols = []
for row in coeffs:
for block in row:
# ZigZagスキャン順に
zz = block.reshape(-1)[ZIGZAG_ORDER]
# EOBを求める
eob = np.max(np.nonzero(zz))
# RLE
rl = 0
symbol = []
for v in zz[1:-eob] if eob > 0 else zz[1:]:
if v == 0:
rl += 1
# ゼロランが16続いたらZRL
if rl == 16:
symbol.append((int(0xF0), None))
rl = 0
else:
s, b = __cvt_to_size_and_bits(int(v))
print(rl, v, s, b, (rl << 4) + s)
symbol.append(((rl << 4) + s, b))
rl = 0
if eob > 0:
symbol.append((int(0x00), None))
symbols.append(symbol)
symbols = [symbols[i : i + c] for i in range(0, len(symbols), c)]
return symbols
def huffman_coding(symbols: list[tuple[int, bitarray.bitarray | None]]):
RESERVE = 2048
counts = Counter([_[0] for _ in symbols])
# 予約された符号のためにダミーを追加
counts[RESERVE] = 0
# Huffmanテーブルを構築
ht = bitarray.util.canonical_huffman(counts)[0]
ht.pop(RESERVE)
return ht おつかれさまでした。
今回をもって、アドベントカレンダーにおけるJPEGエンコーダーをつくろうシリーズは終了となります。
全3本の記事すべてが、あまりに取り留めのない形になっており、普段からアウトプットをすることの重要さを痛感しました。つくろうシリーズと呼ぶにはあまりにも断片的になってしまいましたが、もし画像や符号化、JPEGファイルの構造について少しでも興味を持っていただけたなら、ぜひとも調べていただき、記事にしていただけるととても嬉しいです。
それでは、ここまでお付き合いいただきありがとうございました。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。