2025年02月05日
こんにちは。新入社員のLです。
今回は1月末に行われた勉強会の内容をお伝えしようと思います。
まずはFさんの発表です。
FさんはAtomic Designについていろいろ説明しました。実は私がフロントエンドについて全然馴染んでいないですが、Fさんの発表内容に対して逆に共感得られますね。
なぜなら、Atomic Designは「最も小さい単位からコンポーネントを設定し、コードの再利用を最大化する方法論」ですから、フロントエンドに詳しくない私にとっては、難解なフロントエンドフレームワークよりもずっと直感的で面白く感じますね。
Atomic Designの中には原子(Atoms)、分子(Molecules)、有機体(Organisms)、テンプレート(Templates)、ページ(Pages)があります。
Atomsの性質は:
1. 他のコンポーネントを含めてはならず、ネイティブ要素やフレームワーク特有の要素を使用します。
2. 独自のマークアップとスタイルを持ちます。
3. 特定のUIやロジックに密接に結びつけません。
4. アプリケーション(または高レベル)状態に直接アクセスしません。
5. UIやレイアウト以外の副作用を持ちません。
6. アプリケーション特有のビジネスロジックを実装しません。
Moleculesの性質は:
1. 1つ以上のAtomで構成されるコンポーネントです。
2. 内部状態を管理できます。
3. 上記の2、3、4、5、6。
Organismの性質は:
1. 複数のAtomやMolecule、他のOrganismで構成される複雑なコンポーネントです。
2. 独自のマークアップとスタイルを持ちます。
3. アプリケーション特有のデータを取得できます。
4. アプリケーション特有のビジネスロジックを実装できます。
5. アプリケーション(または高レベル)状態と接続できます。
6. アプリの特定の領域(UIやロジック)に密接に結びつけることができます。
Templateの性質は:
1. 複数のOrganismのレイアウトを調整するコンポーネントです。
2. 独自のマークアップとスタイルを持ちます。
3. 必要に応じてpropsを受け渡しは可能です。
4. アプリケーション(または高レベル)状態にアクセスしません。
5. UIやレイアウト以外の副作用を持ちません。
6. アプリケーション特有のビジネスロジックを実装しません。
Screens/Pageの性質は:
1. 特定のテンプレートを実装するコンポーネントです。
2. アプリケーション特有のデータを取得できます。
3. アプリケーション特有のビジネスロジックを実装できます。
4. アプリケーション(または高レベル)状態と接続できます。
5. 独自のマークアップやスタイルを持ちません。
Atomic Design利点:
1. 分かりやすいレイアウト。
2. コンポーネントを自由に組み合わせ可能。
3. 簡単に作れるコンポーネントデザインライブラリ。
4. 一貫性のあるコーディング。
5. グローバルなサイト更新。
Code Refactoring利点:
1. コードを読みやすくします。
2. 技術的負債を減らします。
3. ビジネスをよりよく理解します。
4. サポートコストを減らします。
Fさんの発表はこれで終わりました。次回の発表は以下の内容になるらしいですね。
「モバイルアプリArchitecture: 実はWEBアプリでも利用できる???」
次は私Lの発表です。
元々は大学院時代に趣味でゲームのアクション生成の論文を読んだのですが、ちょうど今回の勉強会に使えて嬉しいですね。
モーション生成とは、何かしらの入力、例えば、テキスト、コントロール指示から対象のアニメーションを生成することです。最近たくさんの動画生成AIもリリースされたのですが、モーション生成はそれと違うものです。モーション生成で生成されたアニメーションは、ユーザーが環境(物理演算エンジンとか)の中にインタラクションできるものです。
まずは私が好きだったプロジェクト「AI4Animation」から紹介します。
これは2017年から8年の歴史もあったプロジェクトなんですが、2020年以降、作者がEA(Electronic Arts Inc.)に入職した後の研究は段々とつまらなくなりました(個人的な感想)。また、彼が2022年にMETAに入職したら、2024の研究はVR向けのモーション生成になりました。
時系列的に2017年から2019年までの研究を語ると、最初はヒト型3Dモデルが地形に応じて自動的にモーションを生成する研究です。使ったAIモデルはかなり単純なパーセプトロンで、現実のモーションデータによってトレーニングされました。
その後、2018年の研究の中に、彼らは歩行だけでもいろんな種類のモーションを持つ四足歩行に突破しようとしました。手法として、彼らは一つのバルブネットワークを入れ、AIモデルを出会った環境によってモーションをスイッチできるようにしました。AIモデルは同じく、現実のモーションデータによってトレーニングされるものです。
2019の研究に、彼らは2018年の研究に基づいて、ヒト型3Dモデルをいろんな目標に応じて種類をスイッチできるモーション生成を開発しました。ここでの目標とは、「対象物+ポーズ」を指します。モーションはまだ決まった種類しかないですが、「待機、歩く、走る、座る、開ける、運ぶ、登る」の間にもスイッチできて、穴を抜けるモーションも自律的にスイッチできれば、もはや「指示に応じてモーションを生成できる」ようなものになりました。
(勉強会の中に私が最初に使った例はUnityのMuseAnimateで、それがテキストからモーションを生成するソフトでした。今はすでに2025年、2019年と比べて5年も経ったからですね。)
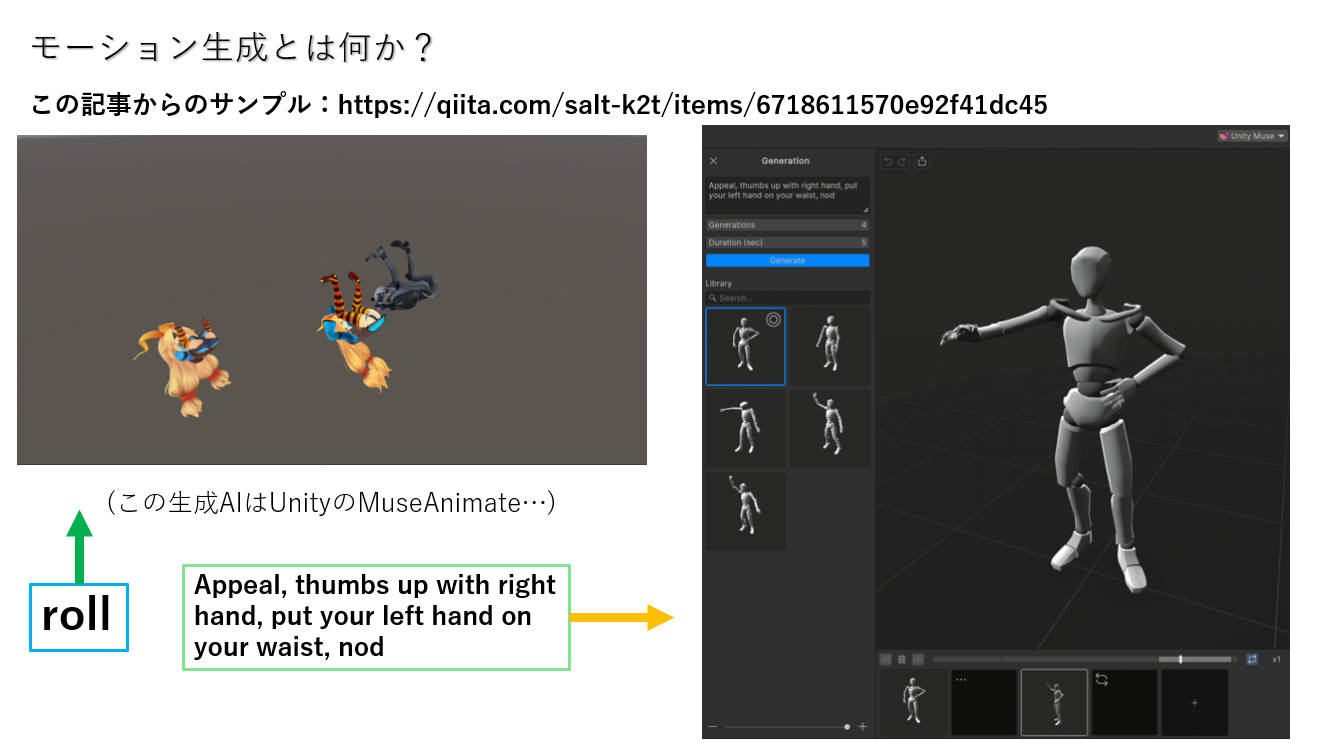
その後、2022年に、Nvidiaが「AI-Driven, Physics-Based Character Animation」を発表しました。このプロジェクトには現実のモーションデータによってトレーニングされたプロトタイプが大量に格納されました。かなりScaling Law的な考え方ですが、その故、似たような手法についての研究は価値が薄れました。使い方としては、目標を設定して強化学習で最適化させてもいいし、文字からモーションを生成することもできます。こうやって、モーション生成は昔よりもずっと便利になりました。
2024年、「Interactive Character Control with Auto-Regressive Motion Diffusion Models」というプロジェクトに、Diffusion Modelと強化学習がうまく融合されました。Diffusion Modelは元々画像生成に広く使われた手法で、「Text to ○○」の実装がいっぱいあるからそれをモーション生成に導入したのかなと思います。Diffusion Modelが画像をノイズから一歩ずつ鮮明な画像にするように、モーション生成のDenoiseは、ある人がある姿勢で異次元から地球に投げられた後、自力(強化学習)で安定しようとする手法です。ノイズ(ほかのモーダルの入力)に近いほど、初期姿勢は安定し難く、強化学習の効果が低くなりますが、最終段階で強化学習がうまくモーションを整うことができます。

結論としては、現段階のモーション生成は文字からでもコントロール指示からでも生成できます。そして物理演算エンジンは強化学習を活かす場所を提供しています。ですが、これだけでアクションアニメーションの進化にはなれていません。なぜなら、2017年~2019年の研究みたいな進化なら既に広く適用されていました。その同時に、アクション映画によく見える、自分の体や武器のさまざまな部分を使って、ターゲットの体や武器のさまざまな場所に接続することは、未だに実現していないです(決まったアニメーションではなくリアルタイム生成)。実現する気があるメーカーもまだ見えません。(NPCの会話生成ならけっこう盛り上がっています)
そうすると、ゲーム内の実運用は多分テキストからモーションを生成するような省力化だけですね。
それ以外、現段階のモーション生成を活用できる方法も少し考えてました。実は目をゲームから逸らせば、そもそもAIによってコマンドで任意の形状のAgentを動かせると考えられます。そこで、もし“Object”を“Agent”として扱えば、VR、ARのUI、さらに、平面UIは、AIと物理演算エンジンを直接利用して、文字や目標設定などの指示の下でフロントエンドなしにバックエンドとのやり取りができるかもしれません。
一方で、仕様が頻繫に変更されるスクリプトコマンド(例えば各種のフレームワーク)より、変わらない数学式で連続的に演算できる、物理演算エンジンの世界は、AIにとってはもっと優しくて、学びやすいでしょう。
将来的に、ハードウェアのスペックが更に高くなれば、デザイナーが「AI+物理演算エンジン」と直接やり取りをするだけで、ユーザーインターフェースが完成できるかもしれません。
次はSさんの発表です。
発表内容はグラフカットと類似度マップという非機械学習手法に基づいたデータ拡張手法です。
データ拡張とは、新しい学習データを生成するための一連の技術です。学習データの量と質はモデルの汎化性能に影響を与えるため、データ拡張は非常に重要です。
簡単なデータ拡張手法なら、元の画像に対して簡単な変換を行い、反転、移動、回転、ノイズ入れなどの方法があります。
物体検出におけるデータ拡張の主な目的は、物体の種類と数を増やすことです。物体検出や分類ネットワークの場合、コピー&ペーストの手法だけでも効果を発揮します。
インスタンスセグメンテーションとは、画像認識技術の一つで、画像内の物体を検出し、それぞれの物体を個別にピクセル単位で分ける手法です。 これにより、同じカテゴリに複数の物体があった場合でも、各物体を個別に識別して物体のマスクを生成することが可能になります。
インスタンスセグメンテーションのピクセルレベルの分類では、データ拡張がより難しくなります。対象物を自由に切り取って別の背景に移動することはできません。なぜなら、それがセグメンテーション結果に影響を与えるためです。
従来の方法では、まず画像内でターゲットの周囲にある類似した色の領域を特定し、その後、ターゲットをその類似した色の領域に移動させます。そして、元の位置はインペインティングを行って処理します。
この方法はターゲットを似た色の背景に移動させるだけのものです。もし画像自体に似た色の背景がない場合、移動の品質に問題が生じる可能性があります。
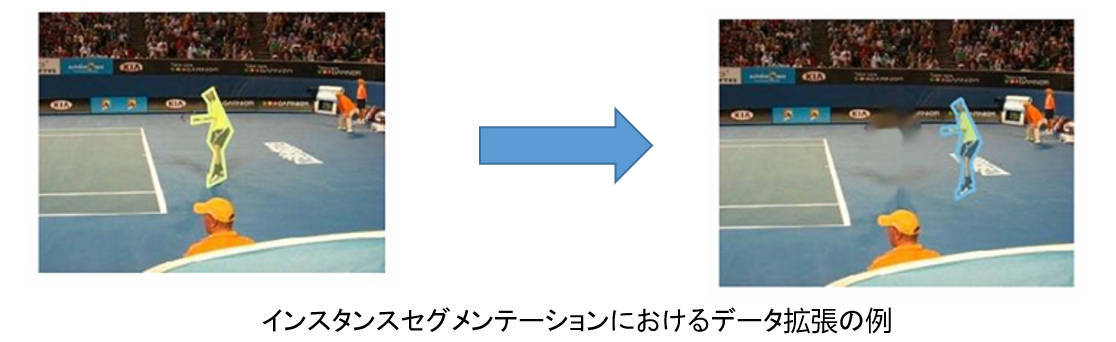
問題を解決するために、グラフカットと類似度マップを使用してデータ拡張を実現します。色の類似度を使って物体を移動させるだけでなく、より自然に移動させることができます。
画像の類似度とは、二つの画像がどれくらい似ているかを示す指標です。
画像の類似度を比較するためのアルゴリズムには、二つのタイプがあります:
1. 画像サイズが同じ場合、各ピクセルごとの差異を計算し、その最終的な平均差または差異の合計を比較します。(例えば、ユークリッド距離)
2. 画像の構造の類似度を反映する方法は、二つの画像の各行におけるピクセルの平均値を計算し、その平均値に基づいて分散を求め、最終的な分散を比較します。

一番目の比較方法では、ピクセルを比較しており、二つの画像の類似度はあまり高くありません。しかし、二番目の方法では、二つの画像の構造が非常に似ています。結果として、二つの評価方法を組み合わせ、それぞれに異なる重みを付けることにしました。
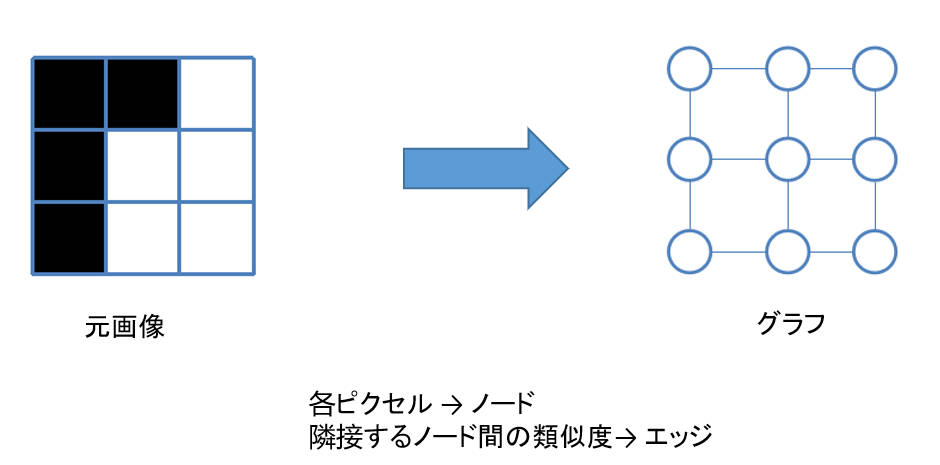
グラフカットに入る前に、まずは画像をグラフで表現する考え方です。画像の場合、無向グラフ G = <V, E> を使って画像を表現できます。V と E はそれぞれノードとエッジの集合です。
そして、Augmentationターゲットを似た色の背景がない場所に移動してうまく融合させるために、最小エッジの集合を持つ融合をAugmentationのグラフカットにします。
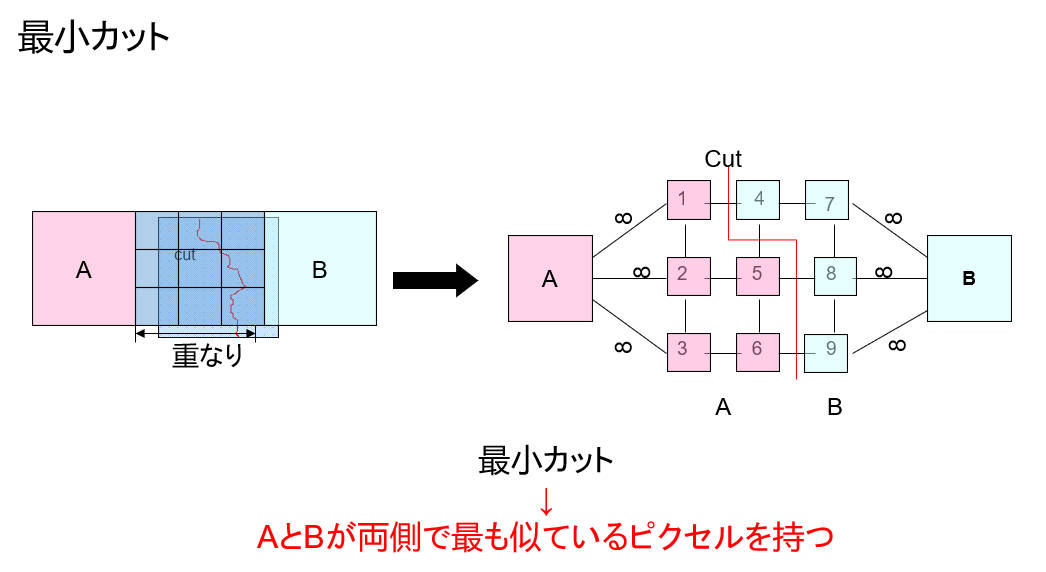
この方法は以下の手順で進めます:
1. 二つのボックスを設定します。一つは保留の部分として使用し、もう一つは画像全体をスキャンします。

2. グラフカットを行うために、類似度を比較して似ている領域を見つける必要があります。(例えば、構造と色の類似性を基にした方法を使用し、高い類似性を持つ300枚以上の画像を取得します。)

3. 高い類似性を持つ領域に対してグラフカットを行います。

4. 領域を置き換えます。

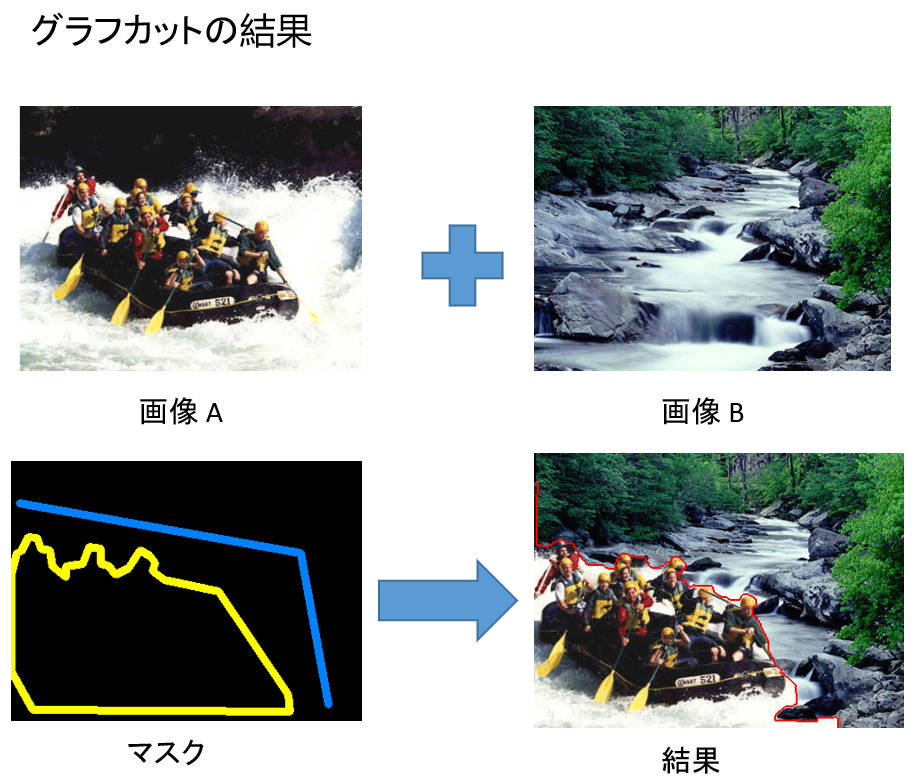
すると、こういう結果になりました。
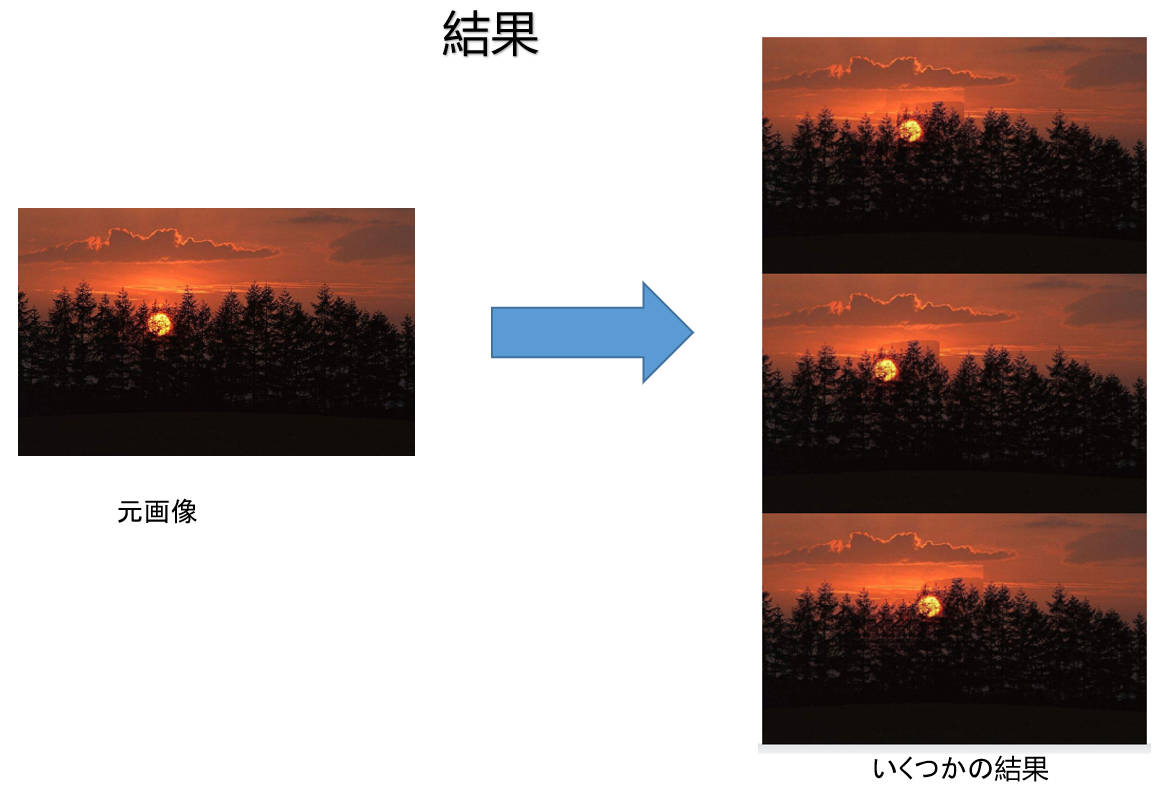
こうして今回、Sさんがグラフカットと類似性マップを組み合わせたデータ拡張手法を提案しました。結果は自然に見えますが、深層学習モデルの性能向上を証明するためには、さらなる実験が必要です。
いかがでしょうか?個人的にはすごくいい出来事だと思いました。深層学習の領域には説明可能な手法はかなり貴重なものなんですからね。
以上は今回の勉強会の全部の発表内容でした。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。