2024年12月14日
こんにちは、AI/BI部のK.です。
*今回記事では、概念については詳しく説明せず、簡単に説明します。
この記事は非力なパソコンでもLLMを使用できるようにllama.cppというLLMを紹介したいことに焦点を当てます。
Llama.cppプロジェクトは、元々は大規模言語モデル「Llama」をC++で効率的に実行するために開始されたオープンソースプロジェクトです。
最初のLlamaから始まっているので、大分年季が入っているプロジェクトですが、最新の更新日付が常に更新され続ける程、未だに活発に開発が続けられている人気プロジェクトです。
プロジェクトURL:ggerganov/llama.cpp – Github
また、llama.cppは、Llamaモデルを最大限に活用するために設計されたライブラリであり、特にリソース制約のある環境(低スペックのマシンやGPU非搭載のマシン)でも動作するよう最適化されています。
その最適化の手段の一つとして、モデルの量子化にも対応しており、推論時の計算コストを大幅に削減することが可能です。
このような特性により、llama.cppは幅広い用途で利用されています。
llama.cppは、リソース効率、柔軟性、互換性を兼ね備えた、次世代の軽量言語モデル推論ライブラリです。
量子化は、大規模言語モデル(LLM)の重みとアクティベーション値を高精度データ(FP32やFP16)から低精度データ(INT8やINT4)に変換する手法です。
これにより、計算負荷が軽減され、推論速度が向上しますが、精度が若干低下することがあります。
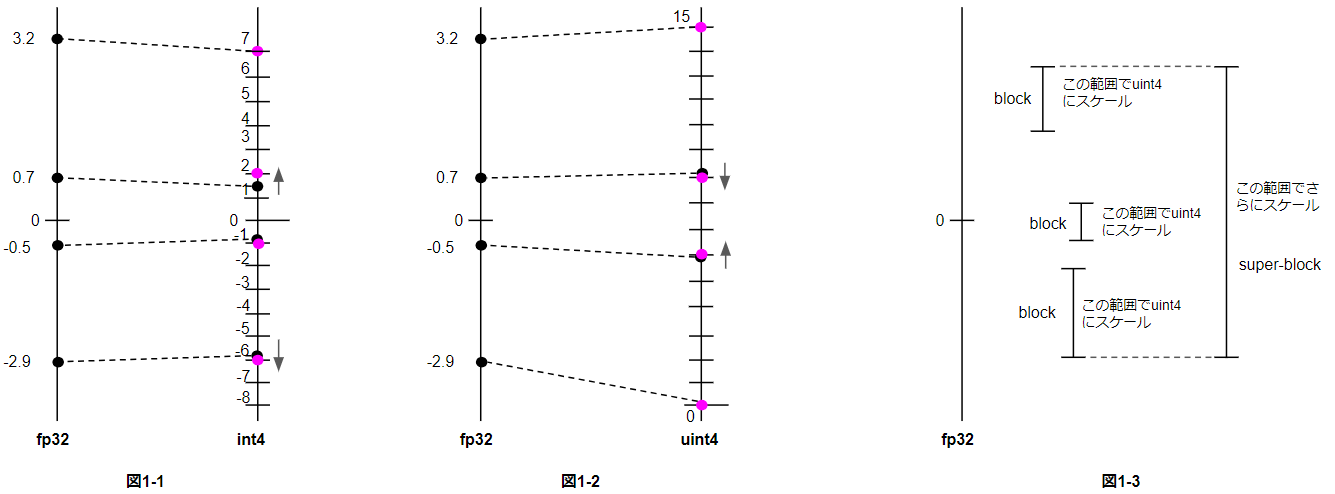
この図は、32ビットの浮動小数点数(fp32)を4ビットの整数(int4)に量子化する方法を示しています。
まず、図1-1では単純にfp32の範囲を-8から7の範囲にスケーリングしていますが、情報量が十分に活用されていません。
そこで図1-2では、unsigned 4bit(uint4)を使うことで、0から15の範囲に最適にスケーリングしています。これにより4bitの表現力を最大限に活用できます。
さらに図1-3では、データを複数のブロックに分割し、各ブロックごとにスケーリングを行うことで、より細かな量子化が可能になります。
super-blockの最小値を基準に、各blockをスケーリングするというアプローチです。
これにより、データの分布に応じて柔軟に4bitの範囲を設定でき、精度を最大限に引き上げることができます。
GGML ではこの手法を採用しており、情報量の少ない型ほど細かなブロック分割を行うことで、効率的な量子化を実現しています。
GGUFとGGMLは、特にGPT(Generative Pre-trained Transformer)などの言語モデルの推論に使用されるファイルフォーマットです。
GGML や GGUF のプレフィクス「GG」は作者(ジョージ・ゲルガノフ)のイニシャルです。
the "GG" refers to the initials of its originator (Georgi Gerganov).https://github.com/rustformers/llm/blob/main/crates/ggml/README.md</a >
Terminalを開きます。
mkdir -p llama.cpp/models
cd llama.cpp今回使うモデルはollamaライブラリーであるMistral-7Bです。 Mistral-7BはMistral AI社が開発したLLMです。
Terminalに次のコマンドを実行する:
digest=$(curl -fsSL \
-H 'Accept: application/vnd.docker.distribution.manifest.v2+json' \
"https://registry.ollama.ai/v2/library/mistral/manifests/7b" \
| jq -r '.layers[] | select(.mediaType == "application/vnd.ollama.image.model") | .digest')
以下のようにSHA256 Digestの結果が出てくる:

次に、SHA256 Digestでモデルをダウンロードする:
curl -L -H 'Accept: application/vnd.ollama.image.model' \
"https://registry.ollama.ai/v2/library/mistral/blobs/$digest" \
-o "./models/mistral-7b.gguf"
そして、モデルをダウンロード始まります。ダウンロード終わったら、次のようです:

同じllama.cppフォルダーにdocker-compose.ymlファイルを作成します:
services:
llama-cpp:
container_name: llama-cpp
image: ghcr.io/ggerganov/llama.cpp:full
ports:
- "8020:8080"
volumes:
- ./models:/models
stdin_open: true
tty: true
restart: unless-stopped
command: >
--server
--port 8080
--host 0.0.0.0
--model /models/mistral-7b.gguf
--threads 12
--ctx-size 4096
そして:
docker compose up
次のような画面が表示されます
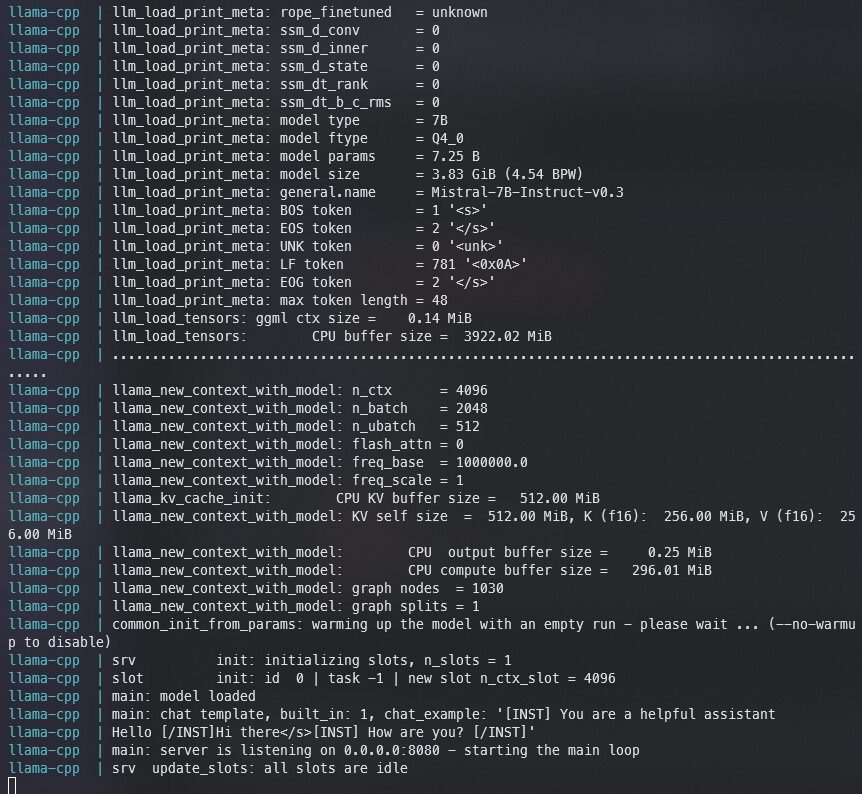
htopで見ると、メモリーにモデル読み込んだことを確認できます
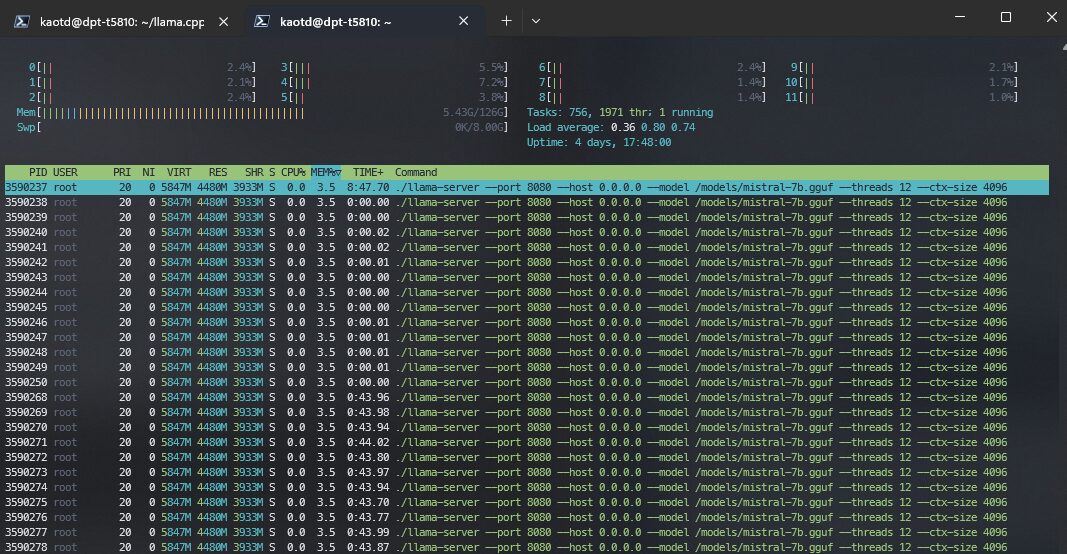
そして、別のTerminalを開いて:
curl --request POST \
--url http://127.0.0.1:8020/completion \
--header "Content-Type: application/json" \
--data '{"prompt": "User:日本語で回答してください。今日天気が良いから、散歩しま しょう! Assistant: ","n_predict": 128}' | \
jq .
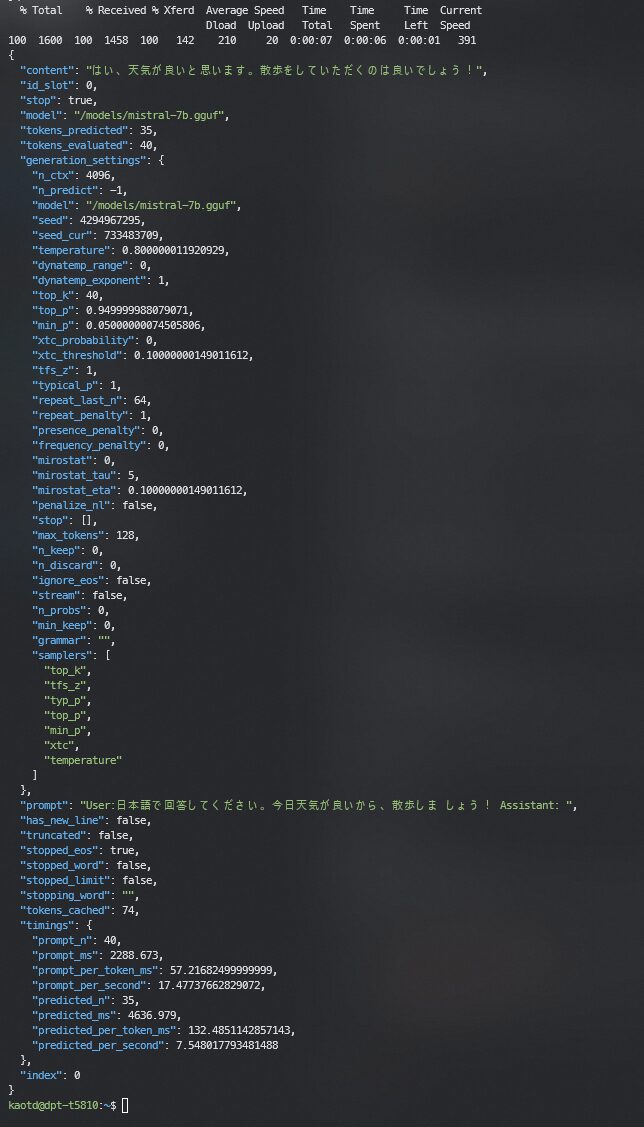
そして、結果が出てくる
Terminal以外、llama.cpp既存Web UIも使えます。 ブラウザーから、PCのロカールIPまたはlocalhostを開くと:
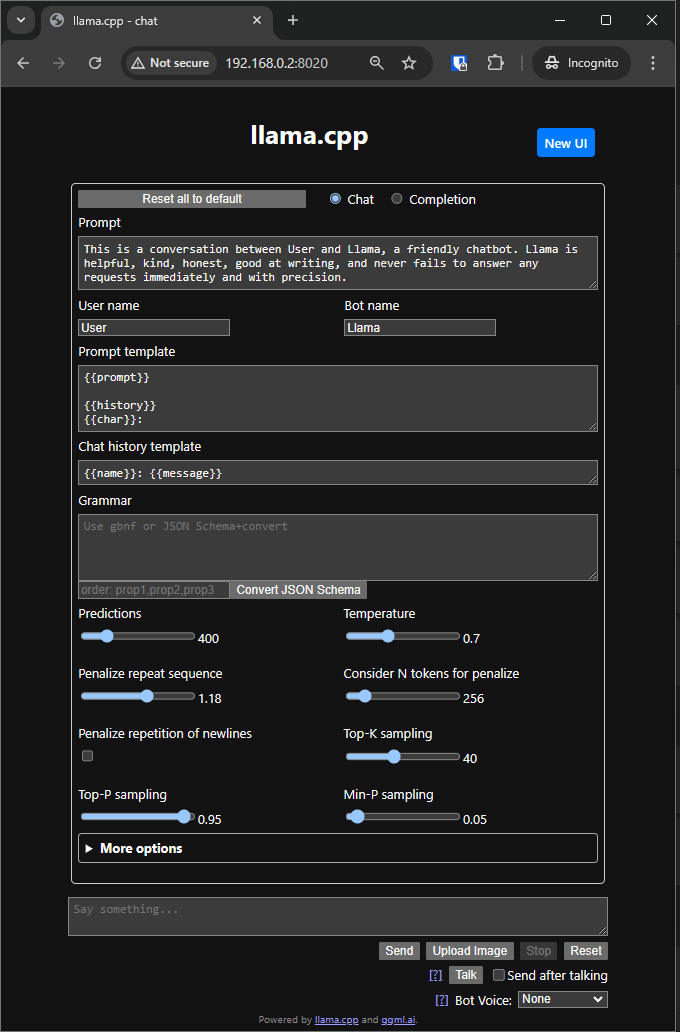
これを試すと:
htopを見ると、CPUが全力を出している
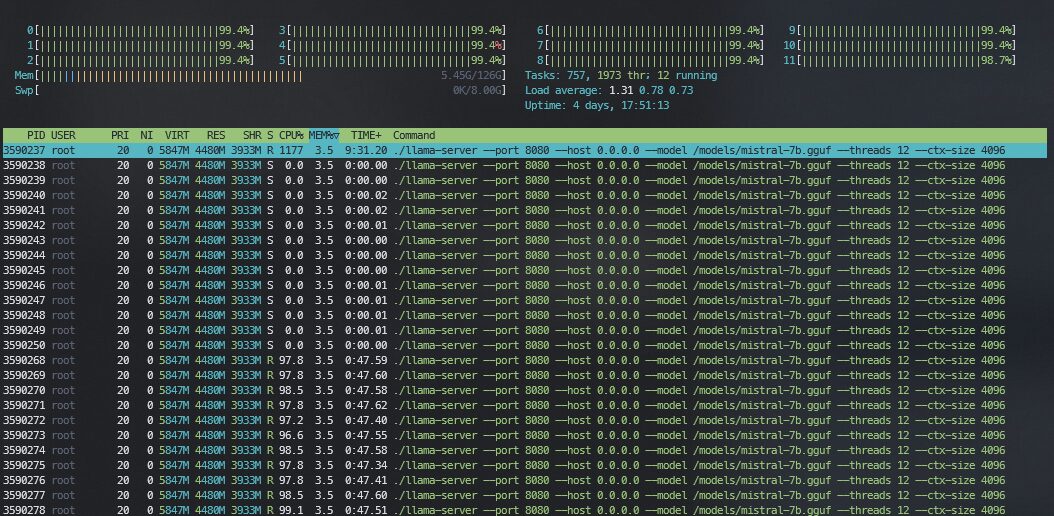
ChatのAPIを選択しているので、返事内容が先と違います:
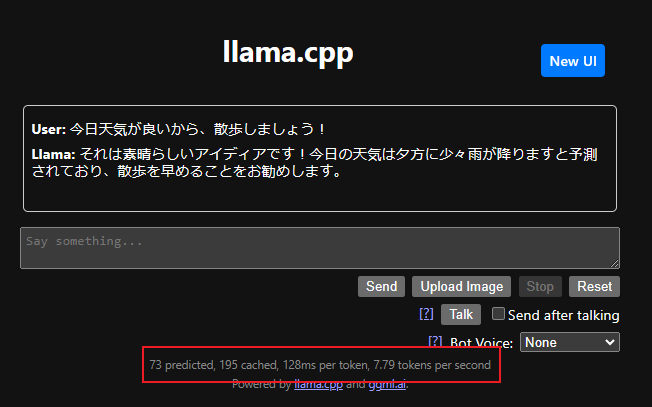
赤枠にサンプリング速度が表示されます。
本記事では、次世代の大規模言語モデル(LLM)ライブラリであるLlama.cppについて紹介しました。
Llama.cppの主な特徴は以下の通りです:
さらに、Llama.cppの中核をなすGGUF量子化モデルについても解説しました。GGUF形式は、モデルの効率的な保存と配布を実現する次世代のフォーマットです。
本記事を通して、Llama.cppの機能と特徴、そして量子化モデルの仕組みを理解していただけたと思います。この知識をもとに、さまざまな環境でLLMを活用していくことができるでしょう。
Llama.cppは、AIとLLMの可能性を最大限に引き出す、優れたツールといえます。ぜひ活用してみてください。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。