2024年11月20日
新人社員のLです。今回はYOLOモデルをTensorRTにExportする方法を紹介します。
まずはAnacondaをダウンロードしてみましょう:
“https://www.anaconda.com/download“
このサイトに入ってから「skip registration」をクリックしてダウンロードページに入ります。

するとインストーラーの選択画面が出ますので、
自分のシステムに合わせてInstallerをダウンロードしてください。
インストールする際、Windowsの方はインストール手順に従えば大丈夫です。Linuxの方は、コマンド「bash installer.sh」を実行してください。installerにさきほどダウンロードしたInstallerファイルを置き換えてください。
これでAnacondaはインストールできます。そしてAnaconda3フォルダとその中のScriptsフォルダのパスを環境変数に入れることは忘れないようにしてください。
後、コマンド「conda init」と[conda activate]を実行すれば、anaconda環境が起動されます。(conda init bashなら.bashrcに、conda init zshなら.zshrcに初期化されます。)
YOLOをインストールする前に、一つ新しいAnaconda環境を作ろう。
このコマンド「conda create –name env_name python=version」で新しいAnaconda環境を作れますが、env_nameに環境の名前を置き換えて、そしてversionに指定したいpythonバージョンを置き換えてください。
新しいAnaconda環境が出来た後、「conda activate env_name」を実行すれば、新しい環境に切り替えられます。
・
次は、Pytorchをインストールする手順です。”https://pytorch.org/“
上記のサイトに入って自分のシステムとGPUに適したpytorchをインストールしてください。
(2024/11/19訂正:悲報/朗報?→https://news.yahoo.co.jp/articles/a69637c370074c54ce171d3ba4a8e2f052ab257b、PyTorchが公式の「Anaconda」チャンネルを廃止する予定なので、今後のpytorchインストールはPipを使いましょう。)

自分のGPUに適したCUDAバージョンは何かというと、”https://developer.nvidia.com/cuda-gpus“、まずはこのサイトで自分のGPUを探し出してください(AMD-YESの方はごめんなさい)。
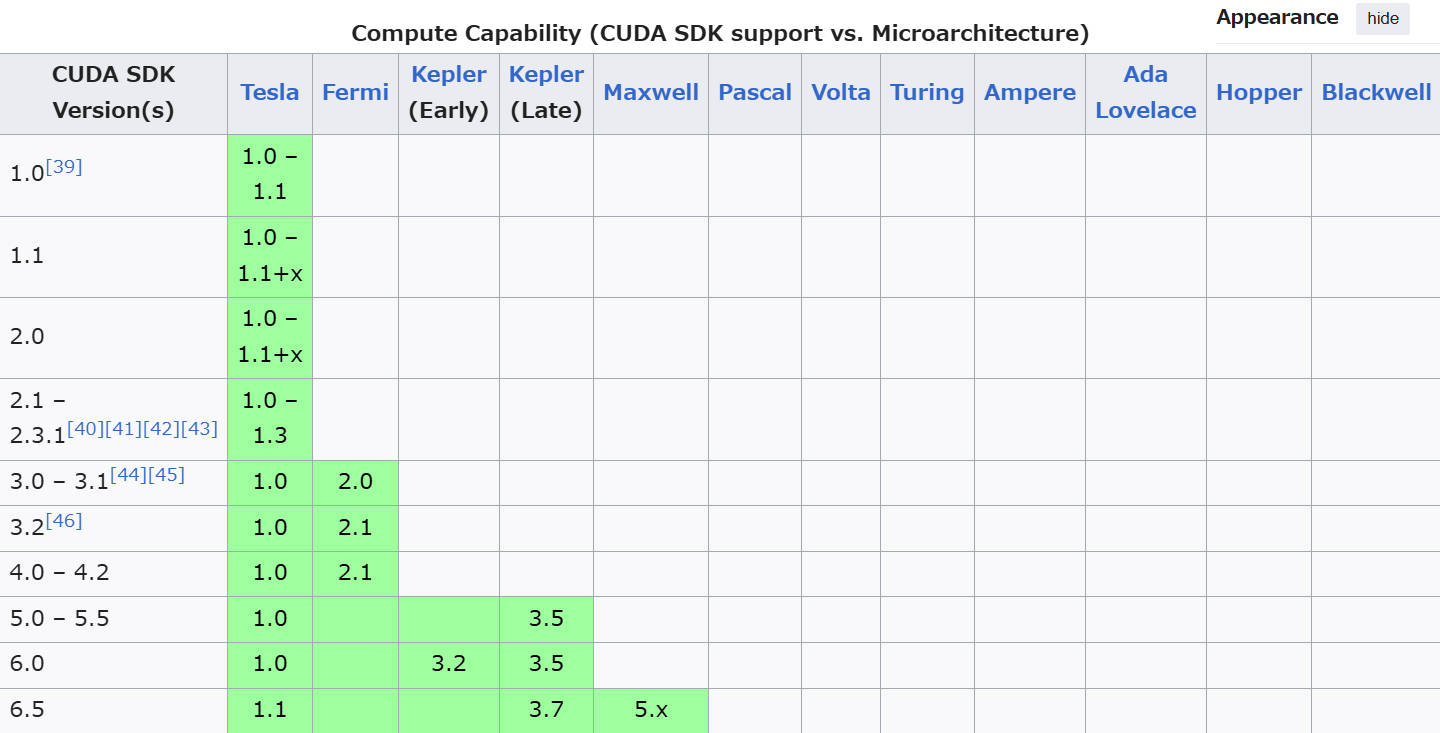
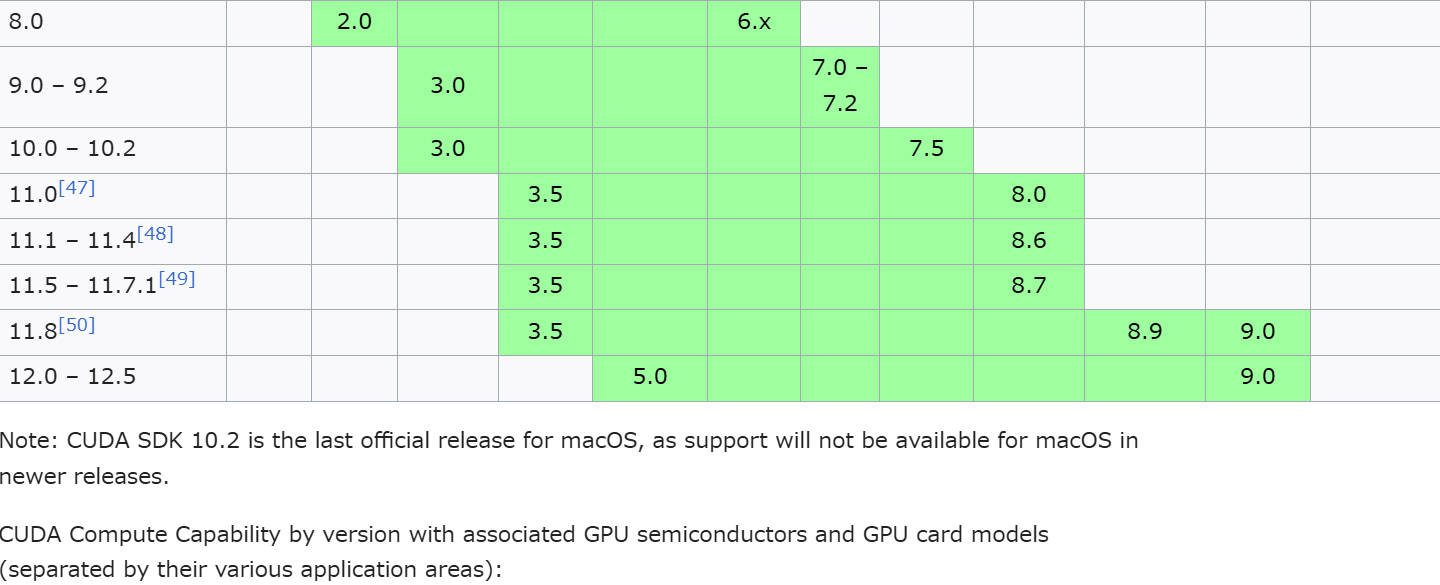
Compute Capabilityがわかったら、またCUDAの(英語バージョンの!)wikiに入ってください。”https://en.wikipedia.org/wiki/CUDA“。そこには「GPUs supported」というサブタイトルがあって、その下のスプレッドシートを参照してください。そして自分のGPUのCompute Capabilityが緑の区間に当てはまっているものの中で、一番新しいCUDA SDK Versionを選択すれば問題ありません。
例えば、GeForce RTX 4090の場合、Compute Capabilityは8.9だから、CUDA 12.4のpytorchを何も考えずにインストールすればOK。
Pytorchを さっき作ったAnacondaの仮想環境 にインストールした後、いよいよYOLOをインストールするステップです。
“https://github.com/ultralytics/ultralytics“、公式のgithubに参照すると、コマンド「pip install ultralytics」を実行すれば、YOLOのモジュール自体はインストールできます。
・
今回の記事はトレーニングの記事ではないので、只軽くトレーニングのやり方を説明します。
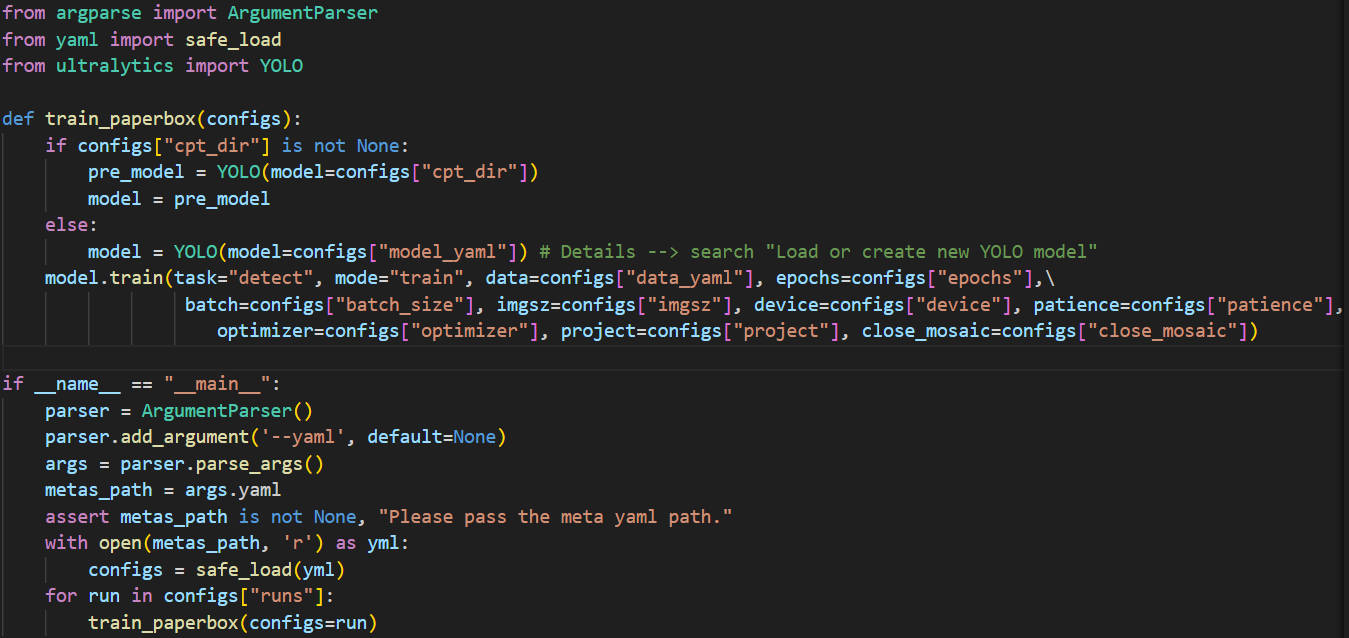
トレーニングはここまで。
・
トレーニングして.ptというモデルの重みファイルを取得すると、それを使ってTensorRTモデルをExportします。詳細はこの記事を参照してください、”https://docs.ultralytics.com/modes/export/“。
簡単に言うと、上記のAnaconda環境の下に下記のコマンドを実行します。
「yolo export model=path/to/model.pt format=engine simplify=True」、modelは.ptファイルのパス、formatは出力のタイプ、simplifyは”Simplifies the model graph”—つまり不要な重みをゼロにすることでスピードアップさせる操作です。
すると、一つの.onnxファイルと.engineファイルが出力されます。.engineファイルを使って、コードに「model =

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。