2024年05月08日
どうもこんにちは、Kです。
今回は3月末に社内で行われた勉強会についてです。
今回はペルソナで製品導入に向けたデザイン と AI・MLにおける音声処理・話者認識モデルの話です。早速見ていきましょう〜
まず、ペルソナで製品導入に向けたデザインについてです。
自社のECサイトパッケージ「PavoMart」のサービスについて社内で共有しました。

企業間の注文のやり取りをオンラインでできるプラットフォームで、
発注者はこのプラットフォームで希望の商品を注文できます。
そして、受注者はプラットフォームと連携されたSalesforceで注文内容を確認できます。
PavoMartとは、簡単に言うと「カスタマイズ可能なtoB向け Salesforceで管理できるECサイト」サービスです。

そもそも「PavoMart」の「Pavo」はクジャクという意味で、そこからはマジカルバナナのように連想を続け、
「クジャク」→「カラフル」→「沢山の色」→「沢山」→「沢山の商品」→「沢山の商品を取り扱うECサイト」と
少し強引なところもありますが…。
そして クジャクは羽を広げるととてつもなく大きく見えますよね、その部分からも取っていて クジャクが羽を大きく広げる様に、
このサービスを利用するお客様がビジネスを広げれる様に…という意味が込められています。

今回 作成した、簡単なペルソナ。
「ペルソナ」とはターゲットをより具体的な人物として落とし込んだものです。
お客様とヒアリングする段階で、そのサイトを利用するターゲットを絞ります。
その後、上げてもらったターゲットを更に具体的にする為に、
「こういう人、いるよね」レベルの ユーザーイメージ、ペルソナを作成します。
そのユーザーイメージを開発するメンバーに共有することにより、必要な機能や求めるデザインを確率することが容易になります。
チームのメンバーの様々な世代や性別 等がありますから、ペルソナを軸にイメージを固めるのは大切です。



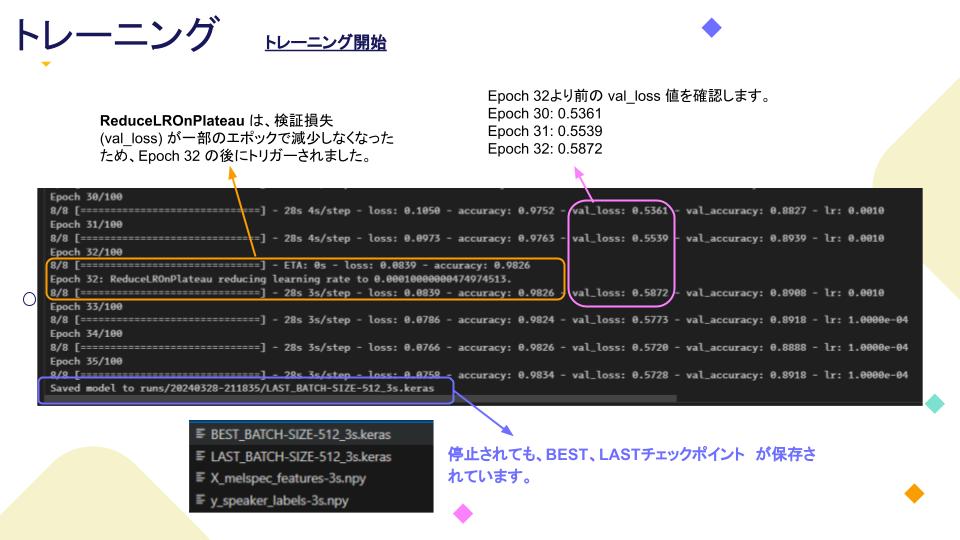
モデル作成できましたので、トレニンーグに進みます。トレニンーグするには、「EarlyStopping」、「ModelCheckpoint」、「ReduceLROnPlateau」というコールバックを使います。
EarlyStoppingのpatience値は10、ModelCheckpointはsave_best_only、ReduceLROnPlateauのfactorは0.1、patienceは7に設定します。
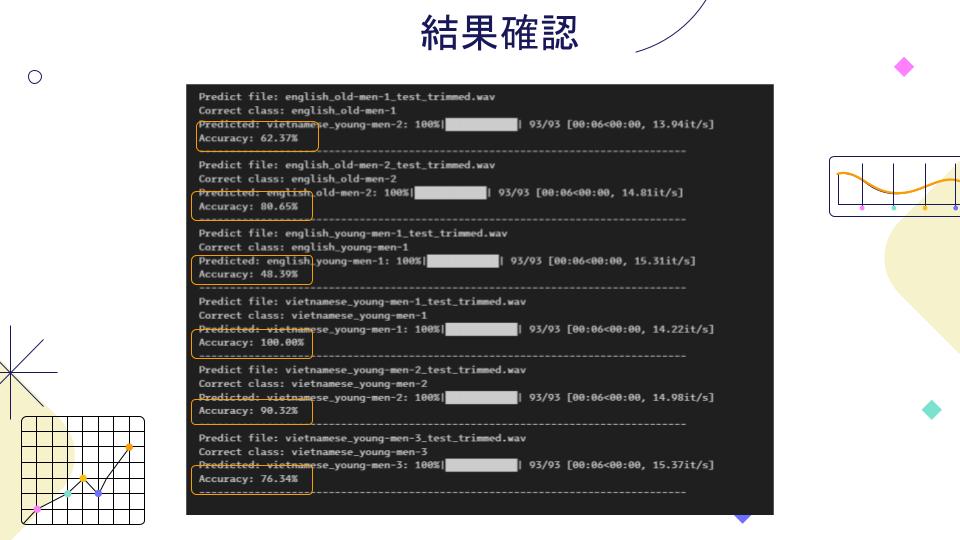
トレニンーグしたモデルをテストデータセットで確認すると、非常に良い感じですが、1つのクラスのデータセット量はほかのクラスよりかなり多いので、Confusion Matrixに異常なところが出てきました。

検証用データを作成して、overlappingという技術を使って、トレニンーグしたモデルで検証判定しました。
トレニンーグデータセットも、検証用データにもまだ色々なところに騒音、雑音などが混んでしまったので、
総合的な制度が下がってしまいました。
これからの精度向上には、まずデータセットの処理は騒音、雑音、沈黙ギャップなどを切り捨てが必要で、
各クラスのデータ量を等しくする必要となります。
今月の勉強会は以上になります、ではまた。

我们每个月都会举办一次全体员工的学习会。
学习会的发表内容是UIUX、Salesforce、figma等,大家会发表自己和工作相关的事情或者是自己有兴趣等等的东西。
发表的人会通过输出知识而对自己目前所有的知识进行整理,
其他员工也获得了了解发表的人的想法和新知识的好机会。

在您加入公司后,公司将会对您进行培训。
今年度所学的是HTML,CSS,JavaScript的基础编程
在这一年的下半年,我们通过Google-NewsAPI取得新闻来制作了一个新闻网站。
我们使用Docker构建了一个容器环境,并开发了一个函数来显示在客户端使用API检索的新闻。
我们的团队使用了Bootstrap和Vue.js等框架
制作出了动态设计和非同时处理的网站
 日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
日本でビジネスを行う上で、日本語でのコミュニケーション能力が重要であることは言うまでもありません。
ソホビービーでは海外からの新入社員向けに週3回日本語講師を招き、就業前の時間を利用し日本語レッスンを実施し、来日1年後の日本語検定N1合格に向けて日本語のトレーニングを行っています。
Salesforceの認知度と普及率の高まりから、当社ではSalesforce導入支援の案件が増加しています。
当社ではSalesforce 認定アドミニストレータ合格を目標に、新卒研修として約2週間Salesforceの講座を行います。
関連サービスのPardot、Tableauについても実践形式で研修を行うため、実務で扱う際にも抵抗なく取り組むことが出来るようになります。
入社後は開発研修を行います。
今年度はHTML、CSS、JavaScriptの基礎的なコーディングについて学び
後半ではGoogle-NewsAPIで取得したニュースでニュースサイト作成を行いました。
Dockerによりコンテナ環境を構築し、APIを用いて取得したニュースをクライアント側で表示する機能を開発。
チーム毎にBootstrapや、Vue.jsといったフレームワークを用いて
レスポンシブ対応デザイン、非同期処理等を駆使してページを作成していきました。
毎月1回、当社では全体で勉強会を行っています。
発表内容はUIUX、Salesforce、figmaなど、仕事関連や関心のある事などそれぞれの好きなことを発表しています。
発表者はアウトプットを通じて知識を整理し、
他の社員は発表者の考えていることや新しい知識を知れる良い機会となっています。